제3과목: 데이터베이스 구축 (41~60번)

| 정보처리기사 필기 기출문제 | |||||
| 24년 3회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 24년 2회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 24년 1회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 23년 3회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 23년 2회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 23년 1회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
41. 데이터 모델의 구성 요소가 아닌 것은?
① 속성(Attribute)
② 연산(Operation)
③ 관계(Relationship)
④ 개체(Entity)
| 데이터 모델의 3요소 (구-연-제) 구조 (Structure) : 데이터베이스에 논리적으로 표현될 데이터 객체들 간의 관계를 정의 - 개체(Entity), 속성(Attribute), 관계(Relationship) 등 연산 (Operations) : 데이터베이스에 저장된 실제 데이터를 처리하는 작업 명세를 정의 - 릴레이션(테이블)을 조작하는 기본 도구 제약 조건 (Constraints) : 데이터베이스에 저장될 수 있는 실제 데이터의 논리적인 제약 규칙 - 데이터의 무결성을 유지하기 위한 조건 답: 2번 |
42. 시스템 카탈로그(System Catalog)에 대한 설명으로 옳지 않은 것은?
① 사용자, 객체에 대한 정의나 명세에 관한 정보를 유지 관리하는 시스템 테이블이다.
② 일반 이용자도 SQL을 이용하여 내용을 검색하거나 수정할 수 있다.
③ DBMS가 스스로 생성하고 유지한다.
④ 데이터 디렉터리, 번역기, 질의 최적화기 등으로 구성된다.
| 시스템 카탈로그 (데이터 사전) - 시스템 카탈로그 내의 각 테이블은 사용자를 포함하여 DBMS에서 지원하는 모든 데이터 객체에 대한 정의나 명세에 관한 정보를 유지 관리하는 시스템 테이블 - 카탈로그들이 생성되면 데이터 사전에 저장되기 때문에 좁은 의미로는 카탈로그를 데이터 사전(Data Dictionary)이라고도 한다. - 시스템 카탈로그에 저장된 정보를 메타 데이터(Meta-Data)라고 한다. - 카탈로그 자체도 시스템 테이블로 구성되어 있어 일반 이용자도 SQL을 이용하여 내용을 검색해 볼 수 있다. - INSERT, DELETE, UPDATE문으로 카탈로그를 갱신하는 것은 허용되지 않는다. - 데이터베이스 시스템에 따라 상이한 구조를 갖는다. - 카탈로그는 DBMS가 스스로 생성하고 유지한다. 답: 2번 생성, 유지 및 수정은 못 한다. 조회만 가능하다. |
43. 관계대수에 대한 설명으로 옳지 않은 것은?
① 원하는 릴레이션을 정의하는 방법을 제공하며 비절차적 언어이다.
② 릴레이션 조작을 위한 연산의 집합으로 피연산자와 결과가 모두 릴레이션이다.
③ 일반 집합 연산과 순수 관계 연산으로 구분된다.
④ 질의에 대한 해를 구하기 위해 수행해야 할 연산의 순서를 명시한다.
| 관계대수 - 관계형 데이터베이스에서 원하는 정보와 그 정보를 검색하기 위해서 어떻게 유도하는가를 기술하는 절차적인 언어 - 관계대수는 릴레이션을 처리하기 위해 연산자와 연산규칙을 제공하는 언어로 피연산자가 릴레이션이고, 결과도 릴레이션이다. - 질의에 대한 해를 구하기 위해 수행해야 할 연산의 순서를 명시한다. 순수 관계 연산자 Select ( σ ) : 릴레이션에서 특정 조건을 만족하는 튜플(행)을 구하는 연산 Project ( π ) : 릴레이션에서 주어진 속성(열) 리스트에 해당하는 값들만 추출하는 연산 Join ( ⋈ ) : 공통 속성을 중심으로 두 개의 릴레이션을 하나로 합쳐서 새로운 릴레이션을 만듦 Division ( ÷ ) : 릴레이션 S의 모든 조건을 만족하는 릴레이션 R의 튜플들을 추출 일반 관계 연산자 UNION (합집합, ∪) INTERSECTION (교집합, ∩) DIFFERENCE (차집합, ㅡ) CARTESIAN PRODUCT (교차곱, X) 답: 1번 |
44. DML에 해당하는 것으로만 나열된 것은?
ㄱ. SELECT ㄴ.UPDATE ㄷ.INSERT ㄹ.GRANT
① ㄱ, ㄴ, ㄷ
② ㄱ, ㄴ, ㄹ
③ ㄱ, ㄷ, ㄹ
④ ㄱ, ㄴ, ㄷ, ㄹ
| DML (Data Manipulation Language, 데이터 조작어) : 테이블 내의 실제 데이터를 조회, 삽입, 수정, 삭제할 때 사용 - SELECT: 데이터 조회 - INSERT: 데이터 삽입 - UPDATE: 데이터 수정 - DELETE: 데이터 삭제 DDL (Data Definition Language, 데이터 정의어) : 데이터베이스 구조(테이블, 인덱스, 뷰 등)를 생성, 변경, 삭제할 때 사용 - CREATE: 구조 생성 - ALTER: 구조 변경 - DROP: 구조 삭제 - TRUNCATE: 테이블의 모든 데이터 삭제 (구조는 남김) DCL (Data Control Language, 데이터 제어어) : 데이터의 보안, 무결성, 회복, 병행 제어 등을 위해 사용합니다. - GRANT: 권한 부여 - REVOKE: 권한 취소 - COMMIT / ROLLBACK: 트랜잭션 제어 답: 1번 |
45. 개체 관계 모델에 대한 설명으로 옳지 않은 것은?
① 오너-멤버(Owner-Member) 관계라고도 한다.
② 개체 타입과 이들 간의 관계 타입을 기본 요소로 이용하여 현실 세계를 개념적으로 표현한다.
③ E-R 다이어그램에서 개체 타입은 사각형으로 나타낸다.
④ E-R 다이어그램에서 속성은 타원으로 나타낸다.
| E-R 모델 (개체 관계 모델) - 피터 첸(Peter Chen)에 의해 제안 - E-R 모델은 개체 타입(Enitiy Type)과 이들 간의 관계 타입(Relationship Type)을 이용해 현실 세계를 개념적으로 표현한다. - E-R 모델에서는 데이터를 개체(Entity), 관계(Relationship), 속성(Attribute)으로 묘사한다. - E-R 모델은 특정 DBMS를 고려한 것은 아니다. - E-R 다이어그램으로 표현하며, 1:1, 1:N, N:M 등의 관계 유형을 제한 없이 나타낼 수 있다. E-R다이어그램 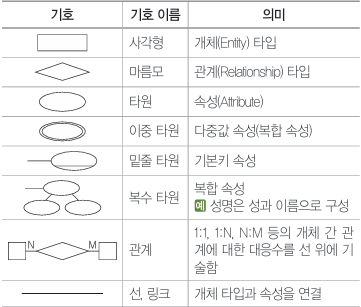 답: 1번 오너-멤버(Owner-Member) 관계는 E-R 모델이 아니라 망(네트워크) 데이터 모델에서 사용하는 용어 |
46. 릴레이션에 R1에 속한 애튜리뷰트의 조합인 외래키를 변경하려면 이를 참조하고 있는 R2의 릴레이션의 기본키도 변경해야 하는데 이를 무엇이라고 하는가?
① 정보 무결성
② 고유 무결성
③ 키 제약성
④ 참조 무결성
| 무결성 제약 조건 개체 무결성 (Entity Integrity) : 기본키(Primary Key)는 NULL 값을 가질 수 없으며, 중복될 수도 없음 - 테이블에서 각 튜플(행)을 유일하게 식별해야 하기 때문 참조 무결성 (Referential Integrity) : 외래키(Foreign Key) 값은 참조하는 테이블의 기본키 값과 동일하거나, NULL이어야 함 - 존재하지 않는 데이터를 참조하는 오류를 방지하기 위함 (예: 없는 부서 번호를 사원 정보에 입력할 수 없음) 도메인 무결성 (Domain Integrity) : 특정 속성(열)의 값은 그 속성에 정의된 도메인(범위)에 속한 값이어야 함 - '성별'이라는 속성에 '남', '여' 외의 값이 들어오면 안 되는 규칙 답: 4번 "외래키" + "참조" → 참조 무결성 |
47. 아래 그림에서 트리의 차수(degree)를 구하면?

① 2
② 3
③ 4
④ 5
| 차수(디그리)는 노드들 중 가장 많은 수 → 차수(디그리)는 3개(E) 단말노드는 자식이 하나도 없는 노드 → 4개(I,J,G,H) 답: 2번 |
48. 정규화 과정 중 1NF에서 2NF가 되기 위한 조건은?
① 1NF를 만족하고 모든 도메인이 원자 값이어야 한다.
② 1NF를 만족하고 키가 아닌 모든 애트리뷰트들이 기본 키에 이행적으로 함수 종속되지 않아야 한다.
③ 1NF를 만족하고 다치 종속이 제거되어야 한다.
④ 1NF를 만족하고 키가 아닌 모든 속성이 기본키에 완전 함수적 종속되어야 한다.
| 정규화 (도부이결다조) 1NF (제1정규형): 도메인이 원자 값 (다중 값 제거) 2NF (제2정규형): 부분 함수적 종속 제거 (완전 함수적 종속 만족) 3NF (제3정규형): 이행적 함수적 종속 제거 (X → Y 이고 Y → Z 이면 X → Z) BCNF: 결정자이면서 후보키가 아닌 것 제거 4NF (제4정규형): 다치 종속 제거 5NF (제5정규형): 조인 종속 제거 답: 4번 ①번: 1NF(제1정규형)의 정의입니다. (원자 값) ②번: 3NF(제3정규형)가 되기 위한 조건입니다. (이행적 함수 종속) ③번: 4NF(제4정규형)가 되기 위한 조건입니다. (다치 종속) |
49. 병행제어 기법 중 로킹에 대한 설명으로 옳지 않은 것은?
① 로킹의 대상이 되는 객체의 크기를 로킹 단위라고 한다.
② 데이터베이스, 파일, 레코드 등은 로킹 단위가 될 수 있다.
③ 로킹의 단위가 작아지면 로킹 오버헤드가 증가한다.
④ 로킹의 단위가 커지면 데이터베이스 공유도가 증가한다.
| 병행제어 기법의 종류 로킹 (Locking) - 주요 데이터의 액세스를 상호 배타적으로 하는 것 - 트랜잭션들이 어떤 로킹 단위를 액세스하기 전에 Lock(잠금)을 요청해서 Lock이 허락되어야만 그 로킹 단위를 액세스할 수 있도록 하는 기법 로킹 단위 - 병행제어에서 한꺼번에 로킹할 수 있는 객체의 크기를 의미 - 데이터베이스, 파일, 레코드, 필드 등이 로킹 단위가 될 수 있다. - 로킹 단위가 크면 로크 수가 작아 관리하기 쉽지만 병행성 수준이 낮아지고, + 공유도 감소 - 로킹 단위가 작으면 로크 수가 많아 관리하기 복잡해 오버헤드가 증가하지만 병행성 수준은 높아진다. + 공유도 증가 답: 4번 |
50. 다음 중 파티션에 대한 설명으로 틀린 것은?
① 파티셔닝으로 인해 쿼리 성능은 향상되지만, 백업 및 복구 속도는 느려진다.
② 파티셔닝된 테이블은 물리적으로 별도의 세그먼트에 저장된다.
③ 파티션은 하나의 테이블을 작은 논리적 단위로 나눈 것이다.
④ 파티셔닝을 수행하면 데이터 가용성이 향상된다.
| 파티션 - 대용량의 테이블이나 인덱스를 작은 논리적 단위인 파티션으로 나누는 것 - 대용량 DB의 경우 중요한 몇 개의 테이블에만 집중되어 데이터가 증가되므로, 이런 테이블들을 작은 단위로 나눠 분산시키면 성능 저하를 방지할 뿐만 아니라 데이터 관리도 쉬워진다. 파티션의 장점 - 테이블은 하나처럼 보이지만 물리적으로는 별도의 공간(세그먼트)에 저장되어 관리가 용이합니다. - 특정 파티션에 장애가 발생하더라도 다른 파티션의 데이터는 그대로 사용할 수 있어 전체 시스템의 가용성이 높아집니다. - 데이터가 분산되어 저장되므로 I/O 분산 효과가 있고, 쿼리 수행 속도가 빨라집니다. - 파티셔닝을 하면 전체 데이터베이스를 한꺼번에 백업하는 대신, 파티션 단위로 나누어 백업하고 복구할 수 있습니다. 따라서 백업 및 복구 작업이 더 빠르고 쉬워집니다. 답: 1번 |
51. 다음 SQL 문에서 괄호 안에 들어갈 내용으로 옳은 것은?
UPDATE MEMBER ( ) GRADE = 'GOLD' WHERE POINT >= 1000;
① SET
② FROM
③ INTO
④ IN
| INSERT → INTO → VALUES (삽입) SELECT → FROM → WHERE (조회) UPDATE → SET → WHERE (수정) DELETE → FROM → WHERE (삭제) 답: 1번 |
52. 분산 데이터베이스 목표 중 "데이터베이스의 분산된 물리적 환경에서 특정 지역의 컴퓨터 시스템이나 네트워크에 장애가 발생해도 데이터 무결성이 보장된다."는 것과 관계있는 것은?
① 장애 투명성
② 병행 투명성
③ 위치 투명성
④ 중복 투명성
| 분산 데이터베이스의 목표 위치 투명성 (Location Transparency) - 액세스하려는 데이터베이스의 실제 위치를 알 필요 없이 단지 데이터베이스의 논리적인 명칭만으로 액세스할 수 있음 중복 투명성 (Replication Transparency) - 동일 데이터가 여러 곳에 중복되어 있떠라도 사용자는 마치 하나의 데이터만 존재하는 것처럼 사용하고, 시스템은 자동으로 여러 자료에 대한 작업을 수행함 병행 투명성 (Concurrency Transparency) - 분산 데이터베이스와 관련된 다수의 트랜잭션들이 동시에 실현되더라도 그 트랜잭션의 결과는 영향을 받지 않음 장애 투명성 (Failure Transparency) - 트랜잭션, DBMS, 네트워크, 컴퓨터 장애에도 불구하고 트랜잭션을 정확하게 처리함 답: 1번 |
53. 데이터베이스 설계 단계와 그 단계에서 수행되는 작업의 연결이 잘못된 것은?
① 요구 조건 분석 - 트랜잭션 모델링
② 물리적 설계 단계 - 목표 DBMS에 맞는 물리적 구조 설계
③ 논리적 설계 단계 - 목표 DBMS에 종속적인 논리 스키마 설계
④ 구현 단계 - 목표 DBMS DDL로 스키마 작성
| 데이터베이스 설계 단계별 특징 (요구-개-논-물-구현) 1. 요구 조건 분석 (Requirement Analysis) - 사용자의 요구사항을 수집하고 분석하여 '요구 조건 명세서'를 작성합니다. 2. 개념적 설계 (Conceptual Design) - 개념 스키마 모델링과 트랜잭션 모델링을 병행 수행한다. - 요구 분석 단계에서 나온 결과인 요구 조건 명세를 DBMS에 독립적인 E-R 다이어그램으로 작성한다. - DBMS에 독립적인 개념 스키마를 설계한다. 3. 논리적 설계 (Logical Design) - 개념 세계의 데이터를 필드로 기술된 데이터 타입과 이 데이터 타입들 간의 관계로 표현되는 논리적 구조의 데이터로 모델화한다. - 개념 스키마를 설계하는 단계라면 논리적 설계에서는 개념 스키마를 평가 및 정제하고 DBMS에 따라 서로 다른 논리적 스키마를 설계하는 단계이다. - 트랜잭션의 인터페이스를 설계한다. - 관계형 데이터베이스라면 테이블을 설계하는 단계이다. 4. 물리적 설계 (Physical Design) - 다양한 데이터베이스 응용에 대해 처리 성능을 얻기 위해 데이터베이스 파일의 저장 구조 및 액세스 경로를 결정한다. - 저장 레코드의 양식, 순서, 접근 경로, 조회가 집중되는 레코드와 같은 정보를 사용하여 데이터가 컴퓨터에 저장되는 방법을 묘사한다. - 물리적 설계 시 고려할 사항 : 트랜잭션 처리량, 응답 시간, 디스크 용량, 저장 공간의 효율화 등 5. 구현 (Implementation) - DDL을 사용하여 실제 데이터베이스와 테이블을 생성합니다. 답: 1번 트랜잭션 모델링은 개념적 설계부터 시작 |
54. 다음 질의어를 SQL 문장으로 바르게 나타낸 것은? (단, 사원 테이블에 사원코드, 이름, 부서의 열이 있다고 가정한다.)
부서가 인사, 사원코드가 3000 이하인 사원의 사원코드에 1000을 더하라.
① UPDATE 사원코드 SET 사원코드+1000 WHERE 부서="인사" OR 사원코드<=3000;
② UPDATE 사원 SET 사원코드=사원코드+1000 WHERE 부서="인사" OR 사원코드<=3000;
③ UPDATE 사원코드 SET 사원코드+1000 WHERE 부서="인사" AND 사원코드<=3000;
④ UPDATE 사원 SET 사원코드=사원코드+1000 WHERE 부서="인사" AND 사원코드<=3000;
| 보기를 보면서 푸는게 쉽다 1. UPDATE 사원코드 SET 사원코드+1000 UPDATE 사원 SET 사원코드=사원코드+1000 UPDATE [테이블명] SET [컬럼명, 수식] → 그러므로 UPDATE 사원 SET 사원코드-사원코드+1000 이 맞다 2. WHERE 부서="인사" OR 사원코드<=3000; WHERE 부서="인사" AND 사원코드<=3000; '부서가 인사, 사원코드가 3000이하' → AND(~이고, ~이면서) 조건문이 맞다. (OR이 되려면 인사 또는 사원코드가 3000이하라고 적었어야함) 답: 4번 |
55. 분산 데이터베이스의 장점으로 거리가 먼 것은?
① 지역 자치성이 높다.
② 잠재적 오류가 감소한다.
③ 분산 제어가 가능하다.
④ 효용성과 융통성이 높다.
| 분산 데이터베이스의 장점 - 지역 자치성이 높음 - 자료의 공유성이 향상됨 - 분산 제어가 가능함 - 시스템 성능이 향상됨 - 중앙 컴퓨터의 장애가 전체 시스템에 영향을 끼치지 않음 - 효용성과 융통성이 높음 - 신뢰성 및 가용성이 높음 - 점진적 시스템 용량 확장이 용이함 분산 데이터베이스의 단점 - DBMS가 수행할 기능이 복잡함 - 데이터베이스 설계가 어려움 - 소프트웨어 개발 비용이 증가함 - 처리 비용이 증가함 - 잠재적 오류가 증가함 분산 데이터베이스의 목표 - 위치 투명성 : 액세스하려는 데이터베이스의 실제 위치를 알 필요 없이 단지 데이터베이스의 논리적인 명칭만으로 액세스할 수 있음 - 중복 투명성 : 동일 데이터가 여러 곳에 중복되어 있떠라도 사용자는 마치 하나의 데이터만 존재하는 것처럼 사용하고, 시스템은 자동으로 여러 자료에 대한 작업을 수행함 - 병행 투명성 : 분산 데이터베이스와 관련된 다수의 트랜잭션들이 동시에 실현되더라도 그 트랜잭션의 결과는 영향을 받지 않음 - 장애 투명성 : 트랜잭션, DBMS, 네트워크, 컴퓨터 장애에도 불구하고 트랜잭션을 정확하게 처리함 분산 데이터베이스 시스템의 주요 구성 요소 - 분산 처리기 (Distributed Processor): 자체적인 처리 능력을 가지며 지리적으로 분산되어 있는 컴퓨터 시스템입니다. - 분산 데이터베이스 (Distributed Database): 지리적으로 분산되어 있는 데이터베이스입니다. - 통신 네트워크 (Communication Network): 분산 처리기들을 연결하여 자원을 공유할 수 있도록 하는 통신망입니다. 답: 2번 "분산"이라는 말이 나오면 "성능과 가용성은 좋아지지만, 복잡해져서 관리나 설계는 힘들어진다"고 기억 |
56. 다음 문장의 ( ) 안 내용으로 공통 적용될 수 있는 가장 적절한 내용은 무엇인가?
- 관계형 데이터 모델에서 한 릴레이션의 ( )는 참조되는 릴레이션의 기본 키와 대응되어 릴레이션 간에 참조 관계를 표현하는데 사용되는 중요한 도구이다.
- ( )를 포함하는 릴레이션이 참조하는 릴레이션이 되고, 대응되는 기본 키를 포함하는 릴레이션이 참조 릴레이션이 된다.
① 후보키(Candidate Key)
② 대체키(Alternate Key)
③ 외래키(Foreign Key)
④ 수퍼키(Super Key)
| 키 (Key) 후보키 (Candidate Key) - 릴레이션을 구성하는 속성들 중에서 튜플을 유일하게 식별하기 위해 사용하는 속성들의 부분집합 - 기본키로 사용할 수 있는 속성들을 말함 - 후보키는 릴레이션에 있는 모든 튜플에 대해서 유일성과 최소성을 만족시켜야 함. 기본키 (Primary Key) - 후보키 중에서 특별히 선정된 주키(Main Key)로 중복된 값을 가질 수 없음 - 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성 - 기본키는 NULL 값을 가질 수 없음. 대체키 (Alternate Key) - 후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키를 의미 - 보조키 슈퍼키 (Super Key) - 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키로서 릴레이션을 구성하는 모든 튜플들 중 슈퍼키로 구성된 속성의 집합과 동일한 값은 나타나지 않음 - 슈퍼키는 릴레이션을 구성하는 모든 튜플에 대해 유일성은 만족시키지만, 최소성은 만족시키지 못 함 외래키 (Foreign Key) - 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합을 의미 - 한 릴레이션에 속한 속성 A와 참조 릴레이션의 기본키인 B가 동일한 도메인 상에서 정의되었을 때의 속성 A를 외래키라고 함 답: 3번 |
57. 다음 중 트리거(Trigger)에 대한 설명으로 틀린 것은?
① 데이터 변경 및 무결성 유지, 로그 메시지 출력 등의 목적으로 사용된다.
② 트리거의 생성문에는 반드시 값을 반환하는 RETURN 명령어가 사용되어야 한다.
③ 데이터의 삽입, 갱신, 삭제 등의 이벤트가 발생할 때마다 관련 작업이 자동으로 수행되는 절차형 SQL이다.
④ CREATE TRIGGER 명령어를 통해 생성된다.
| 트리거 (Trigger) - 데이터베이스 시스템에서 데이터의 삽입(Insert), 갱신(Update), 삭제(Delete)등의 이벤트가 발생할 때마다 관련 작업이 자동으로 수행되는 절차형 SQL - 트리거는 데이터베이스에 저장되며, 데이터 변경 및 무결성 유지, 로그 메시지 출력 등의 목적으로 사용된다. - 트리거의 구문에는 DCL(데이터 제어어)을 사용할 수 없으며, DCL이 포함된 프로시저나 함수를 호출하는 경우에도 오류가 발생한다. - 트리거에 오류가 있는 경우 트리거가 처리하는 데이터에도 영향을 미치므로 트리거를 생성할 때 세심한 주의가 필요하다. - CREATE TRIGGER 명령어를 사용하여 정의 답: 2번 트리거는 특정 조건이 충족되면 자동으로 실행되는 '동작' 그 자체에 목적이 있으므로, 별도의 반환 값(Return Value)을 가지지 않음. 따라서 "반드시 RETURN 명령어가 사용되어야 한다"는 설명은 틀렸다. |
58. 데이터베이스의 특성으로 옳은 내용 모두를 나열한 것은?
ㄱ. 실시간 접근성 ㄴ. 동시 공용 ㄷ. 계속적인 변화 ㄹ. 내용에 의한 참조
① ㄱ, ㄴ, ㄷ
② ㄱ, ㄴ, ㄹ
③ ㄴ, ㄷ, ㄹ
④ ㄱ, ㄴ, ㄷ, ㄹ
| 데이터베이스의 특성 실시간 접근성 (Real-Time Accessibility) - 사용자의 질의(Query)에 대하여 즉시(실시간) 처리하여 응답할 수 있어야 합니다. 동시 공용 (Concurrent Sharing) - 여러 사용자가 서로 다른 목적으로 데이터베이스의 데이터를 동시에 사용할 수 있어야 합니다. 계속적인 변화 (Continuous Evolution) - 데이터베이스에 저장된 내용은 삽입(Insert), 삭제(Delete), 갱신(Update)을 통해 항상 최신의 정확한 데이터를 유지하며 변해야 합니다. 내용에 의한 참조 (Content Reference) - 데이터를 찾을 때 데이터가 저장된 물리적 주소(Address)나 위치가 아닌, 사용자가 요구하는 데이터의 내용(값)에 따라 참조합니다. 답: 4번 주요 오답 유형 : "주소에 의한 참조", "정적인 상태 유지" |
59. DBMS의 필수 기능 중 사용자와 데이터베이스 사이의 인터페이스 수단을 제공하는 기능은?
① Definition 기능
② Control 기능
③ Manipulation 기능
④ Strategy 기능
| 데이터베이스 관리 시스템 필수 기능 정의 기능 (Definition Facility) : 틀(구조) 만들기 - 데이터의 구조(스키마)를 정의하고, 물리적 저장 장치와의 매핑을 설정하는 기능 - 데이터 모델에 맞는 논리적 구조와 물리적 구조 간의 변환을 제공 조작 기능 (Manipulation Facility) : 데이터 다루기 (사용자 인터페이스) - 사용자와 데이터베이스 사이의 인터페이스 역할 - 사용자가 데이터를 검색(SELECT), 삽입(INSERT), 삭제(DELETE), 갱신(UPDATE)할 수 있도록 하는 도구와 수단을 제공 제어 기능 (Control Facility) : 무결성, 보안, 공유 관리 - 데이터의 정확성과 보안을 유지하기 위한 기능 - 무결성 유지, 보안 및 권한 검사, 병행 제어(Concurrency Control) 등을 담당 답: 3번 |
60. 뷰(View)에 대한 설명으로 옳지 않은 것은?
① 뷰는 CREATE 문을 사용하여 정의한다.
② 뷰는 데이터의 논리적 독립성을 제공한다.
③ 뷰를 제거할 때에는 DROP 문을 사용한다.
④ 뷰는 저장장치 내에 물리적으로 존재한다.
| 뷰 (View) : 사용자에게 접근이 허용된 자료만을 제한적으로 보여주기 위해 하나 이상의 기본 테이블로부터 유도된, 이름을 가지는 가상 테이블 → 테이블을 참조하는 가상 테이블이므로, 참조하고 있는 테이블이 삭제되면 뷰(View)도 삭제된다. 뷰 (View) 특징 - 뷰는 기본 테이블로부터 유도된 테이블이기 때문에 기본 테이블과 같은 형태의 구조를 사용하며, 조작도 기본 테이블과 거의 같다 - 뷰는 가상 테이블이기 때문에 물리적으로 구현되어 있지 않다. → 물리적으로 존재하지 않아서 인덱스를 생성하거나 가질 수 없다. - 데이터의 논리적 독립성을 제공할 수 있다. - 필요한 데이터만 뷰로 정의해서 처리할 수 있기 때문에 관리가 용이하고 명령문이 간단해진다. - 뷰를 통해서만 데이터에 접근하게 하면 뷰에 나타나지 않는 데이터를 안전하게 보호하는 효율적인 기법으로 사용할 수 있다. - 기본 테이블의 기본키를 포함한 속성(열) 집합으로 뷰를 구성해야만 삽입, 삭제, 갱신 연산이 가능하다. (제약) - 일단 정의된 뷰는 다른 뷰의 정의에 기초가 될 수 있다. - 뷰를 정의할 때는 CREATE문, 제거할 때는 DROP문을 사용한다. 답: 4번 |
| 정보처리기사 필기 기출문제 | |||||
| 24년 3회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 24년 2회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 24년 1회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 23년 3회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 23년 2회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 23년 1회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
'자격증 요약 > 정보처리기사' 카테고리의 다른 글
| [23년 3회 3과목] 정보처리기사 필기 문제 풀이 (0) | 2026.01.28 |
|---|---|
| [24년 1회 3과목] 정보처리기사 필기 문제 풀이 (0) | 2026.01.28 |
| [24년 3회 3과목] 정보처리기사 필기 문제 풀이 (0) | 2026.01.27 |
| [23년 1회 5과목] 정보처리기사 필기 문제 풀이 (0) | 2026.01.23 |
| [23년 2회 5과목] 정보처리기사 필기 문제 풀이 (1) | 2026.01.23 |