제2과목: 소프트웨어 개발 (21~40번)

| 정보처리기사 필기 기출문제 | |||||
| 24년 3회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 24년 2회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 24년 1회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 23년 3회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 23년 2회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 23년 1회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
21. 반정규화(Denormalization) 유형 중 중복 테이블을 추가하는 방법에 해당하지 않는 것은?
① 빌드 테이블의 추가
② 집계 테이블의 추가
③ 진행 테이블의 추가
④ 특정 부분만을 포함하는 테이블 추가
| 반정규화 : 시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터 모델을 통합, 중복, 분리하는 과정으로, 의도적으로 정규화 원칙을 위배하는 행위 - 반정규화를 수행하면 시스템의 성능이 향상되고 관리 효율성은 증가하지만 데이터의 일관성 및 정합성, 무결성이 저하될 수 있다. - 과도한 반정규화는 오히려 성능을 저하시킬 수 있다. - 반정규화를 위해서는 사전에 데이터의 일관성과 무결성을 우선으로 할지, 데이터베이스의 성능과 단순화를 우선으로 할지를 결정해야한다. 반정규화 방법 테이블 통합 테이블 분할 - 수평 분할 - 수직 분할 중복 테이블 추가 - 집계 테이블의 추가 - 진행 테이블의 추가 - 특정 부분만을 포함하는 테이블 추가 중복 속성 추가 답: 1번 |
22. 외계인 코드(Alien Code)에 대한 설명으로 옳은 것은?
① 프로그램의 로직이 복잡하여 이해하기 어려운 프로그램을 의미한다.
② 아주 오래되거나 참고문서 또는 개발자가 없어 유지보수 작업이 어려운 프로그램을 의미한다.
③ 오류가 없어 디버깅 과정이 필요 없는 프로그램을 의미한다.
④ 사용자가 직접 작성한 프로그램을 의미한다.
| 소스 코드 최적화 클린 코드(Clean Code) - 가독성 : 누구든지 코드를 쉽게 읽을 수 있도록 작성 - 단순성 : 코드를 간단하게 작성 - 의존성 배제 : 코드가 다른 모듈에 미치는 영향을 최소화 - 중복성 최소화 : 코드의 중복을 최소화 - 추상화 : 상위 클래스/메소드/함수에서는 간략하게 애플리케이션의 특성을 나타내고 상세 내용은 하위 클래스/메소드/함수에서 구현 나쁜 코드(Bad Code) - 스파게티 코드 : 코드의 로직이 서로 복잡하게 얽혀 있는 코드 - 외계인 코드 : 아주 오래되거나 참고문서 또는 개발자가 없어 유지보수 작업이 어려운 코드 ※ 레거시 코드 : 낡은 기술이나 오래된 방법으로 작성되어 현재 시스템에서 다루기 까다로운 코드 ※ 리팩토링 : 결과의 변경 없이 코드의 구조를 개선하여 가독성을 높이고 유지보수를 쉽게 만드는 것 ※ 재공학 : 기존 시스템을 분석하여 새로운 기능을 추가하거나 성능을 개선하며 더 나은 시스템으로 교체하는 것 ※ 역공학 : 이미 만들어진 소프트웨어를 분석하여 설계서나 소스 코드를 추출해 내는 과정 답: 2번 |
23. 디지털 저작권 관리(DRM)의 기술 요소가 아닌 것은?
① 크랙 방지 기술
② 정책 관리 기술
③ 암호화 기술
④ 방화벽 기술
| 디지털 저작권 관리(DRM, Digital Right Management) :저작권자가 배포한 디지털 콘텐츠가 저작권자가 의도한 용도로만 사용되도록 디지털 콘텐츠의 생성, 유통, 이용까지의 전 과정에 걸쳐 사용되는 디지털 콘텐츠 관리 및 보호 기술 - 원본 콘텐츠가 아날로그인 경우에는 디지털로 변환한 후 패키저(Packager)에 의해 DRM 패키징을 수행한다. - 콘텐츠의 크기에 따라 음원이나 문서와 같이 크기가 작은 경우에는 사용자가 콘텐츠를 요청하는 시점에서 실시간으로 패키징을 수행하고, 크기가 큰 경우에는 미리 패키징을 수행한 후 배포한다. - 패키징을 수행하면 콘텐츠에는 암호화된 저작권자의 전자서명이 포함되고 저작권자가 설정한 라이선스 정보가 클리어링 하우스에 등록된다. - 사용자가 콘텐츠를 사용하기 위해서는 클리어링 하우스에 등록된 라이선스 정보를 통해 사용자 인증과 콘텐츠 사용 권한 소유 여부를 확인받아야 한다. - 종량제 방식을 적용한 소프트웨어의 경우 클리어링 하우스를 통해 서비스의 실제 사용량을 측정하여 이용한 만큼의 요금을 부과한다. 디지털 저작권 관리(DRM) 구성요소 - 클리어링 하우스 (Clearing House) : 저작권에 대한 사용 권한, 라이선스 발급, 암호화된 키 관리, 사용량에 따른 결제 관리 등을 수행 - 콘텐츠 제공자 (Contents Provider) : 콘텐츠를 제공하는 저작권자 - 패키저 (Packager) : 콘텐츠를 메타 데이터와 함께 배포 가능한 형태로 묶어 암호화하는 프로그램 - 콘텐츠 분배자 (Contents Distributor) : 암호화된 콘텐츠를 유통하는 곳이나 사람 - 콘텐츠 소비자 (Customer) : 콘텐츠를 구매해서 사용하는 주체 - DRM 컨트롤러 (DRM Controller) : 배포된 콘텐츠의 이용 권한을 통제하는 프로그램 - 보안 컨테이너 (Security Container) : 콘텐츠 원본을 안전하게 유통하기 위한 전자적 보안 장치 디지털 저작권 관리(DRM)의 기술 요소 - 암호화 (Encryption) : 콘텐츠 및 라이선스를 암호화하고 전자 서명을 할 수 있는 기술 - 키 관리 (Key Management) : 콘텐츠를 암호화한 키에 대한 저장 및 분배 기술 - 암호화 파일 생성 (Packager) : 콘텐츠를 암호화된 콘텐츠로 생성하기 위한 기술 - 식별 기술 (Identification) : 콘텐츠에 대한 식별 체계 표현 기술 - 저작권 표현 (Right Expression) : 라이선스의 내용 표현 기술 - 정책 관리 (Policy Management) : 라이선스 발급 및 사용에 대한 정책 표현 및 관리 기술 - 크랙 방지 (Tamper Resistance) : 크랙에 의한 콘텐츠 사용 방지 기술 - 인증 (Authentication) : 라이선스 발급 및 사용의 기준이 되는 사용자 인증 기술 답: 4번 방화벽(Firewall)은 네트워크 보안 기술 |
24. 다음 트리의 차수(Degree)와 단말 노드(Terminal Node)의 수는?
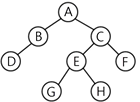
① 차수 : 4, 단말 노드 : 4
② 차수 : 2, 단말 노드 : 4
③ 차수 : 4, 단말 노드 : 8
④ 차수 : 2, 단말 노드 : 8
| 트리 예.  노드(Node) : 트리의 기본 요소로서 자료 항목과 다른 항목에 대한 가지를 합친 것 - 예: A, B, C, D, E, F, G, H, I, J, K, L, M 근 노드(Root Node) : 트리의 맨 위에 있는 노드 - 예: A 디그리(Degree, 차수) : 각 노드에서 뻗어 나온 가지의 수 - 예: A=3, B-2, C=1, D=3 단말 노드(Terminal Node, 잎 노드(Leat Node)) : 자식이 하나도 없는 노드 - 예: K, L, F, G, M, I, J 자식 노드(Son Node) : 어떤 노드에 연결된 다음 레벨의 노드들 - 예: D의 자식 노드 = H, I, J 부모 노드(Parent Node) : 어떤 노드에 연결된 이전 레벨의 노드들 - 예: H의 형제 노드 = I, J 형제 노드(Brother Node, Sibling) : 동일한 부모를 갖는 노드들 - 예: H의 형제 노드 = I, J 트리의 디그리 : 노드들이 디그리 중에서 가장 많은 수 - 예: 노드 A나 D가 3개의 디그리를 가지므로 앞 트리의 디그리는 3이다. 계산 공식 노드와 간선의 관계 : 트리 내의 총 노드 수가 N개라면, 간선의 수는 항상 'N-1'개 이진 트리 : 모든 노드의 차수가 2이하인 트리 답: 2번 |
25. 물리데이터 저장소의 파티션 설계에서 파티션 유형으로 옳지 않은 것은?
① 범위 분할(Range Partitioning)
② 해시 분할(Hash Partitioning)
③ 조합 분할(Composite Partitioning)
④ 유닛 분할(Unit Partitioning)
| 파티션 : 데이터베이스에서 파티션은 대용량의 테이블이나 인덱스를 작은 논리적 단위인 파티션으로 나누는 것을 말한다. 파티션의 종류 범위 분할 (Range Partitioning) - 지정한 열외 값을 기준으로 범위를 지정하여 분할함 - 예. 일별, 월별, 분기별 등 해시 분할 (Hash Partitioning) - 해시 함수를 적용한 결과 값에 따라 데이터를 분할함 - 특정 파티션에 데이터가 집중되는 범위 분할의 단점을 보완한 것으로, 데이터를 고르게 분산할 때 유용함 - 특정 데이터가 어디에 있는지 판단할 수 없음 - 고객번호, 주민번호 등과 같이 데이터가 고른 컬럼에 효과적임 조합 분할 (Compostie Partitioning) - 범위 분할로 분할한 다음 해시 함수를 적용하여 다시 분할하는 방식 - 범위 분할한 파티션이 너무 커서 관리가 어려울 때 유용함 목록 분할 (List Partitioning) - 지정한 열 값에 대한 목록을 만들어 이를 기준으로 분할함 - '국가'라는 열에 '한국', '미국', '일본'이 있는 경우 '미국'을 제외할 목적으로 '아시아'라는 목록을 만들어 분할함 라운드 로빈 분할 (Round Robin Partitioning) - 레코드를 균일하게 분배하는 방식 - 각 레코드가 순차적으로 분배되며, 기본키가 필요 없음 답: 4번 |
26. 형상 관리 도구의 주요 기능으로 거리가 먼 것은?
① 정규화(Normalization)
② 체크인(Check-in)
③ 체크아웃(Check-out)
④ 커밋(commit)
| 형상 관리 도구 주요 기능 저장소 (Repository) 가져오기 (Import) 체크아웃 (Check-Out) 체크인 (Check-In) 커밋 (Commit) 동기화 (Update) 차이 (Diff) 브랜치 (Branch; 가지) 트렁크 (Trunk; 몸통) 답: 1번 정규화는 데이터베이스 설계 시 데이터 중복을 최소화하고 구조를 최적화하는 과정 |
27. 패키지 소프트웨어의 일반적인 제품 품질 요구사항 및 테스트를 위한 국제 표준은?
① ISO/IEC 2196
② IEEE 19554
③ ISO/IEC 12119
④ ISO/IEC 14959
| 품질 요구사항 ISO/IEC 9126 : 소프트웨어의 품질 특성과 평가를 위한 표준 지침으로서 국제 표준으로 널리 사용됨 ISO/IEC 25010 : 소프트웨어 제품에 대한 국제 표준으로, 2011년에 ISO/IEC 9126을 개정하여 만들었음 ISO/IEC 12119 : ISO/IEC 9126을 준수한 품질 표준으로, 패키지 소프트웨어의 품질 요구사항과 이를 검증하기 위한 테스트 절차 규정한 국제 표준 ISO/IEC 14598 : 소프트웨어 품질의 측정과 평가에 필요 절차를 규정한 표준으로, 개발자, 구매자, 평가자 별로 수행해야 할 제품 평가 활동을 규정 ISO/IEC 25010 : ISO/IEC 9126과 ISO/IEC 14598을 통합한 소프트웨어 품질 평가 통합 모델 표준으로, SQuaRF라고도 함 - 기능성 (Functionality) : 사용자의 요구사항을 정확하게 만족하는 기능을 제공하는지 - 신뢰성 (Reliability) : 소프트웨어가 요구된 기능을 정확하고 일관되게 오류 없이 수행할 수 있는 정도 - 사용성 (Usability) : 사용자와 쉽게 배우고, 사용할 수 있는 정도 - 효율성 (Efficiency) : 사용자가 요구하는 기능을 할당된 시간 동안 한정된 자원으로 얼마나 빨리 처리할 수 있는지 정도 - 유지보수성 (Maintainability) : 환경의 변화 또는 새로운 요구사항이 발생했을 때 소프트웨어를 개선하거나 확장할 수 있는 정도 - 이식성 (Portability) : 소프트웨어가 다른 환경에서도 얼마나 쉽게 적용할 수 있는지 정도를 나타냄 답: 3번 12119 → 일일이 테스트해야 하는 패키지 소프트웨어 9126 → 구일이(구리다) 품질이 어떤지 특성을 보자 |
28. 블랙박스 테스트 기법으로 거리가 먼 것은?
① 기초 경로 검사
② 동치 클래스 분해
③ 경계값 분석
④ 원인 결과 그래프
| 블랙박스 테스트 : 소프트웨어의 내부 구조나 코드를 보지 않고, 사용자 요구사항 명세서를 보면서 기능이 정확히 수행되는지 테스트하는 기법 블랙박스 테스트 종류 동치(동등) 분할 검사 (Equivalence Partitioning Testing) 경계값 분석 (Boundary Value Analysis) 원인-효과 그래프 검사 (Cause-Effect Graphing Testing) 오류 예측 검사 (Error Guessing) 비교 검사 (Comparison Testing) 화이트박스 테스트 : 프로그램의 내부 로직(소스 코드)을 직접 보면서 모든 논리적 경로를 테스트합니다 화이트박스 테스트 종류 기초 경로 검사 (Base Path Testing) : 제어 흐름 그래프에서 시작부터 끝까지 가는 독립적인 경로, 싸이클(반복)이 포함될 수 밖에 없음 제어 구조 검사 - 조건 검사 (Condition Testing) - 루프 검사 (Loop Testing) - 데이터 흐름 검사 (Data Flow Testing) 화이트박스 테스트의 검증 기준 문장 (Statement) 검증 기준 - 소스 코드의 모든 구문이 한 번 이상 수행되도록 테스트 케이스 설꼐 분기 (Branch) 검증 기준(결정 (Decision) 검증 기준) - 소스 코드의 모든 조건문에 대해 조건이 True인 경우와 False인 경우가 한 번 이상 수행되도록 테스트 케이스 설계 조건 (Condition) 검증 기준 - 소스 코드의 조건문에 포함된 개별 조건식의 결과가 True인 경우와 False인 경우가 한 번 이상 수행되도록 테스트 케이스 설계 분기/조건 (Branch/Condition) 기준 - 분기 검증 기준과 조건 검증 기준을 모두 만족하는 설계로, 조건문이 True인 경우와 False인 경우에 따라 조건 검증 기준의 입력 데이터를 구분하는 테스트 케이스 설계 답: 1번 |
29. 인터페이스 구현 검증 도구가 아닌 것은?
① ESB
② xUnit
③ STAF
④ NTAF
| 인터페이스 구현 검증 도구 xUnit : 단위 테스트, 자바, C++, NET(NUnit). - 다양한 프로그래밍 언어에서 함수나 클래스 같은 최소 단위(모듈)를 검증하기 위한 도구 STAF : 서비스 중심, 분산 환경, 재사용성, 유연함 - 서비스 호출, 프로그램 실행 등 다양한 환경에서 테스트를 수행할 수 있도록 지원하는 프레임워크입니다. 여러 대의 컴퓨터(분산 환경)에 설치된 테스트 도구들을 통합 관리할 때 유용 FitNesse : 인수 테스트(Acceptance Test), 위키(Wiki) 기반 - 웹 브라우저를 통해 테스트 케이스를 직접 작성하고 실행 결과를 확인할 수 있는 도구입니다. 사용자가 이해하기 쉬운 위키(Wiki) 형태의 인터페이스를 제공하는 것이 가장 큰 특징 NTAF : STAF + FitNesse, 네이버(Naver) 개발 - 위에서 설명한 STAF의 분산 환경 기능과 FitNesse의 협업 기능을 결합하여 네이버에서 만든 테스트 자동화 프레임워크입니다. (시험에는 '두 도구의 결합'이라는 키워드로 자주 등장합니다.) Selenium : 웹 애플리케이션(Web), 브라우저 자동화, 다양한 언어 지원 - 웹 브라우저를 직접 제어하여 웹 사이트의 기능을 테스트하는 도구입니다. 자바스크립트 클릭, 폼 입력 등을 자동으로 수행하며 다양한 브라우저(크롬, 파이어폭스 등)를 지원 watir : Ruby(루비) 기반, 웹 애플리케이션 테스트 - Selenium과 비슷하게 웹 애플리케이션을 테스트하는 도구이지만, Ruby 프로그래밍 언어를 기반으로 만들어진 것이 특징 ※ 인터페이스 통합 기술 EAI : 기업 내 각종 애플리케이션을 통합하는 기술 ESB : EAI의 확장판 개념, 버스 혀애의 통로를 통해서비스 중심으로 통합하는 기술 ※ 테스트 자동화 도구의 분류 정적 분석 도구 : pmd, checkstyle, cppcheck, SonarQube 동적 분석 도구 : xUnit, valance 성능 테스트 도구 : JMeter, LoadRunner 답: 1번 ESB는 테스트 도구가 아니라 서로 다른 애플리케이션들을 통합하여 상호작용할 수 있게 해주는 미들웨어 |
30. 다음 Postfix 연산식에 대한 연산결과로 옳은 것은?
3 4 * 5 6 * +
① 35
② 42
③ 77
④ 360
| 수식의 표기법 전위 표기법 (PreFix) : 연산자 → Left → Right, +AB - 오른쪽에서 왼쪽으로 읽기 중위 표기법 (InFix) : Left → 연산자 → Right, A+B 후위 표기법 (PostFix) : Left → Right → 연산자, AB+ - 왼쪽에서 오른쪽으로 읽기 ※+*34*56 (전위표기법) 단계1 : 6 단계2 : 6,5 단계3 : 6,5,* = 연산자는 바로 앞 숫자 사이에 넣는다. → 30 (6*5) 단계4 : 30,4 단계5 : 30,4,3 단계6 : 30,4,3,* = 연산자는 바로 앞 숫자 사이에 넣는다. → 30,12 (4*3) 단계7 : 30,12,+ = 연산자는 바로 앞 숫자 사이에 넣는다. → 42 (30+12) ※34*56*+ (후위표기법) 단계1 : 3 단계2 : 3,4 단계3 : 3,4,* = 연산자는 바로 앞 숫자 사이에 넣는다. → 12 (3*4) 단계4 : 12,5 단계5 : 12,5,6 단계6 : 12,5,6* = 연산자는 바로 앞 숫자 사이에 넣는다. → 12,30 (5*6) 단계7 : 12,30,+ = 연산자는 바로 앞 숫자 사이에 넣는다. → 42 (12+30) 답: 2번 |
31. 테스트 케이스에 일반적으로 포함되는 항목이 아닌 것은
① 테스트 조건
② 테스트 데이터
③ 테스트 비용
④ 예상 결과
| 테스트 케이스 : 구현된 소프트웨어가 사용자의 요구사항을 정확하게 준수했는지를 확인하기 위해 설계된 입력 값, 실행 조건, 기대 결과 등으로 구성된 테스트 항목에 대한 명세서로, 명세 기반 테스트의 설계 산출물에 해당한다. → 입력 값(테스트 데이터), 실행 조건(테스트 조건), 기대 결과(예상 결과) 테스트 케이스의 주요 구성 요소 - 식별자 - 테스트 항목 - 입력 명세 - 출력 명세 - 환경 설정 - 특수 절차 요구 - 의존성 기술 답: 3번 비용은 테스트 계획서나 전체적인 예산 수립 단계에서 고려할 사항이지, 개별적인 기능을 검증하는 테스트 케이스 문서 안에 매번 들어가는 항목은 아님 |
32. 이진 검색 알고리즘에 대한 설명으로 틀린 것은?
① 탐색 효율이 좋고 탐색 시간이 적게 소요된다.
② 검색할 데이터가 정렬되어 있어야 한다.
③ 피보나치 수열에 따라 다음에 비교할 대상을 선정하여 검색한다.
④ 비교횟수를 거듭할 때마다 검색 대상이 되는 데이터의 수가 절반으로 줄어든다.
| 이진 검색(이분 검색, Binary Search) : 전체 파일을 두 개의 서브파일로 분리해가면서 Key 레코드를 검색하는 방식 (전제조건) 반드시 데이터가 정렬되어 있어야함. (작동원리) 중간값을 선택 → 찾는 값과 중간 값을 비교 → 찾는 값이 중간값보다 작으면 왼쪽 절반을, 크면 오른쪽 절반을 다시 검색 (성능) 한 번 비교할 때마다 검색 대상이 1/2로 줄어들기 때문에 속도가 매우 빠름 - 최악의 경우 검색 효율이 가장 나쁨 답: 3번 이진 검색은 중간 위치를 기준으로 나누지, 피보나치 수열을 이용하지 않음. ※피보나치 수열을 이용하는 방식은 피보나치 검색이라고 함 |
33. 여러 개의 선택 항목 중 하나의 선택만 가능한 경우 사용하는 사용자 인터페이스 요소는?
① 텍스트 박스
② 체크 박스
③ 토글 버튼
④ 라디오 버튼
| UI 요소 체크 박스 (Check Box) : 여러 개의 선택 상황에서 1개 이상의 값을 선택할 수 있는 버튼 라디오 버튼 (Radio Button) : 여러 항목 중 하나만 선택할 수 있는 버튼 텍스트 박스 (Text Box) : 사용자가 데이터를 입력하고 수정할 수 있는 상자 콤보 상자 (Combo Box) : 이미 지정된 목록 상자에 내용을 표시하여 선택하거나 새로 입력할 수 있는 상자 목록 상자 (List Box) : 콤보 상자와 같이 목록을 표시하지만 새로운 내용을 입력할 수 없는 상자 토글 버튼 (Toggle Button) : 두 가지 상태 중 하나를 선택할 때 사용하며, 누를 때마다 상태가 반전되는 버튼 (예. On/Off, 시작/정지) 답: 4번 라디오는 채널을 하나만 맞출 수 있다. 라디오 버튼 = 1개 체크 리스트는 여러 개 체크할 수 있다 체크 박스 = 다중 선택 |
34. 다음 중 스택을 이용한 연산과 거리가 먼 것은?
① 선택 정렬
② 재귀 호출
③ 후위 표현(Post-Fix Expression)의 연산
④ 깊이 우선 탐색
| 선형 구조 : 데이터가 연속적으로, 직선 모양으로 연결된 구조. 데이터 간의 관계가 '1:1' - 리스트 (List) : 순서가 있는 데이터의 집합 (선형 리스트, 연결 리스트) - 스택 (Stack) : 한쪽 끝에서만 삽입/삭제가 일어나는 LIFO(후입선출) 구조 - 큐 (Queue) : 한쪽에서 삽입, 반대쪽에서 삭제가 일어나는 FIFO(선입선출) 구조 - 데크 (Deque) : 양쪽 끝에서 모두 삽입과 삭제가 가능한 구조 비선형 구조 : 데이터가 계층적이거나 그물망처럼 연결된 구조. 데이터 간의 관계가 '1:다' 또는 '다:다' - 트리 (Tree) : 부모-자식 관계가 있는 계층적 구조 (예: 조직도, 디렉토리 구조) - 그래프 (Graph) : 노드와 노드를 잇는 간선으로 이루어진 그물망 구조 (예: 지도, SNS 인맥 관계 스택(Stack) : 가장 나중에 삽입된 자료가 가장 먼저 삭제되는 후입선출(LIFO, Last In First Out) 방식으로 자료를 처리 스택의 응용 분야 - 함수 호출의 순서 제어 - 인터럽트의 처리 - 수식 계산 및 수식 표기법 - 컴파일러를 이용한 언어 번역 - 부 프로그램 호출 시 복귀주소 저장 - 서브루틴 호출 및 복귀 주소 저장 큐(Queue) : 가장 먼저 삽입된 자료가 가장 먼저 삭제되는 선입선출(FIFO, First In First Out) 방식으로 자료를 처리 - 리스트의 한쪽에서는 삽입 작업이 이루어지고 다른 한쪽에서는 삭제 작업이 이루어지도록 구성한 자료 구조 - 큐는 시작과 끝을 표시하는 두 개의 포인터가 있다 답: 1번 ※선택 정렬은 정렬 알고리즘 |
35. 소프트웨어 테스트와 관련한 설명으로 틀린 것은?
① 화이트박스 테스트는 모듈의 논리적인 구조를 체계적으로 점검할 수 있다.
② 블랙박스 테스트는 프로그램의 구조를 고려하지 않는다.
③ 테스트 케이스에는 일반적으로 시험 조건, 테스트 데이터, 예상 결과가 포함되어야 한다.
④ 화이트박스 테스트에서 기본 경로(Basis Path)란 흐름 그래프의 시작 노드에서 종료 노드까지의 서로 독립된 경로로 싸이클을 허용하지 않는 경로를 말한다.
| 테스트 케이스 : 구현된 소프트웨어가 사용자의 요구사항을 정확하게 준수했는지를 확인하기 위해 설계된 입력 값, 실행 조건, 기대 결과 등으로 구성된 테스트 항목에 대한 명세서로, 명세 기반 테스트의 설계 산출물에 해당한다. → 입력 값(테스트 데이터), 실행 조건(테스트 조건), 기대 결과(예상 결과) 블랙박스 테스트 : 소프트웨어의 내부 구조나 코드를 보지 않고, 사용자 요구사항 명세서를 보면서 기능이 정확히 수행되는지 테스트하는 기법 블랙박스 테스트 종류 동치(동등) 분할 검사 (Equivalence Partitioning Testing) 경계값 분석 (Boundary Value Analysis) 원인-효과 그래프 검사 (Cause-Effect Graphing Testing) 오류 예측 검사 (Error Guessing) 비교 검사 (Comparison Testing) 화이트박스 테스트 : 프로그램의 내부 로직(소스 코드)을 직접 보면서 모든 논리적 경로를 테스트합니다 화이트박스 테스트 종류 기초 경로 검사 (Base Path Testing) : 제어 흐름 그래프에서 시작부터 끝까지 가는 독립적인 경로, 싸이클(반복)이 포함될 수 밖에 없음 제어 구조 검사 - 조건 검사 (Condition Testing) - 루프 검사 (Loop Testing) - 데이터 흐름 검사 (Data Flow Testing) 화이트박스 테스트의 검증 기준 문장 (Statement) 검증 기준 - 소스 코드의 모든 구문이 한 번 이상 수행되도록 테스트 케이스 설꼐 분기 (Branch) 검증 기준(결정 (Decision) 검증 기준) - 소스 코드의 모든 조건문에 대해 조건이 True인 경우와 False인 경우가 한 번 이상 수행되도록 테스트 케이스 설계 조건 (Condition) 검증 기준 - 소스 코드의 조건문에 포함된 개별 조건식의 결과가 True인 경우와 False인 경우가 한 번 이상 수행되도록 테스트 케이스 설계 분기/조건 (Branch/Condition) 기준 - 분기 검증 기준과 조건 검증 기준을 모두 만족하는 설계로, 조건문이 True인 경우와 False인 경우에 따라 조건 검증 기준의 입력 데이터를 구분하는 테스트 케이스 설계 답: 4번 |
36. 애플리케이션의 처리량, 응답 시간, 경과 시간, 자원 사용률에 대해 가상의 사용자를 생성하고 테스트를 수행함으로써 성능 목표를 달성하였는지를 확인하는 테스트 자동화 도구는?
① 명세 기반 테스트 설계 도구
② 코드 기반 테스트 설계 도구
③ 기능 테스트 수행 도구
④ 성능 테스트 도구
| 테스트 자동화 도구 정적 분석 도구 (Static Analysis Tools) - 프로그램을 실행하지 않고 분석하는 도구 - 소스 코드에 대한 코딩 표준, 코딩 스타일, 코드 복잡도 및 남은 결함 등을 발견하기 위해 사용 테스트 케이스 생성 도구 (Test Case Generation Tools) - 자료 흐름도 : 자료 원시 프로그램을 입력받아 파싱한 후 자료 흐름도를 작성 - 기능 테스트 : 주어진 기능을 구동시키는 모든 가능한 상태를 파악하여 이에 대한 입력을 작성 - 입력 도메인 분석 : 원시 코드의 내부를 참조하지 않고, 입력 변수의 도메인을 분석하여 테스트 데이터를 작성 - 랜덤 테스트 : 입력 값을 무작위로 추출하여 테스트 테스트 실행 도구 (Test Execution Tools) - 스크립트 언어를 사용하여 테스트를 실행하는 방법, 테스트 데이터와 테스트 수행 방법 등이 포함된 스크립트를 작성한 후 실행 - 데이터 주도 접근 방식 : 스프레드시트에 테스트 데이터를 저장하고, 이를 읽어 실행하는 방식 - 키워드 주도 접근 방식 : 스프레드시트에 테스트를 수행할 동작을 나타내는 키워드와 테스트 데이터를 저장하여 실행하는 방식 성능 테스트 도구 (Performance Tset Tools) - 애플리케이션의 처리량, 응답 시간, 경과 시간, 자원 사용률 등을 인위적으로 적용한 가상의 사용자를 만들어 테스트를 수행 테스트 통제 도구 (Test Control Tools) - 테스트 계획 및 관리, 테스트 수행, 결함 관리 등을 수행하는 도구로, 종류에는 형상 관리 도구, 결함 추척/관리 도구 등이 있음 테스트 하네스 도구 (Test hamess Tools) - 애플리케이션의 컨포넌트 및 모듈을 테스트하는 환경의 일부분으로, 테스트를 지원하기 위해 생성된 코드와 데이터를 의미 - 테스트 하네스의 도구는 테스트가 실행될 환경을 시뮬레이션 하여 컴포넌트 및 모듈이 정상적으로 테스트되도록 함 답: 4번 |
37. 소스 코드 정적 분석(Static Analysis)에 대한 설명으로 틀린 것은?
① 소스 코드를 실행시키지 않고 분석한다.
② 코드에 있는 오류나 잠재적인 오류를 찾아내기 위한 활동이다.
③ 하드웨어적인 방법으로만 코드 분석이 가능하다.
④ 자료 흐름이나 논리 흐름을 분석하여 비정상적인 패턴을 찾을 수 있다.
| 테스트 자동화 도구 정적 분석 도구 (Static Analysis Tools) - 프로그램을 실행하지 않고 분석하는 도구 - 소스 코드에 대한 코딩 표준, 코딩 스타일, 코드 복잡도 및 남은 결함 등을 발견하기 위해 사용 테스트 케이스 생성 도구 (Test Case Generation Tools) - 자료 흐름도 : 자료 원시 프로그램을 입력받아 파싱한 후 자료 흐름도를 작성 - 기능 테스트 : 주어진 기능을 구동시키는 모든 가능한 상태를 파악하여 이에 대한 입력을 작성 - 입력 도메인 분석 : 원시 코드의 내부를 참조하지 않고, 입력 변수의 도메인을 분석하여 테스트 데이터를 작성 - 랜덤 테스트 : 입력 값을 무작위로 추출하여 테스트 테스트 실행 도구 (Test Execution Tools) - 스크립트 언어를 사용하여 테스트를 실행하는 방법, 테스트 데이터와 테스트 수행 방법 등이 포함된 스크립트를 작성한 후 실행 - 데이터 주도 접근 방식 : 스프레드시트에 테스트 데이터를 저장하고, 이를 읽어 실행하는 방식 - 키워드 주도 접근 방식 : 스프레드시트에 테스트를 수행할 동작을 나타내는 키워드와 테스트 데이터를 저장하여 실행하는 방식 성능 테스트 도구 (Performance Tset Tools) - 애플리케이션의 처리량, 응답 시간, 경과 시간, 자원 사용률 등을 인위적으로 적용한 가상의 사용자를 만들어 테스트를 수행 테스트 통제 도구 (Test Control Tools) - 테스트 계획 및 관리, 테스트 수행, 결함 관리 등을 수행하는 도구로, 종류에는 형상 관리 도구, 결함 추척/관리 도구 등이 있음 테스트 하네스 도구 (Test hamess Tools) - 애플리케이션의 컨포넌트 및 모듈을 테스트하는 환경의 일부분으로, 테스트를 지원하기 위해 생성된 코드와 데이터를 의미 - 테스트 하네스의 도구는 테스트가 실행될 환경을 시뮬레이션 하여 컴포넌트 및 모듈이 정상적으로 테스트되도록 함 - 구성요소 : 테스트 드라이버, 테스트 스텁, 테스트 슈트, 테스트 케이스, 테스트 스크립트, 목 오브젝트 ※동적 분석 : 프로그램을 직접 실행하면서 분석 답: 3번 정적 분석은 주로 소프트웨어 자동화 도구를 사용하거나 사람이 직접 코드를 검토하는 방식으로 이루어지므로, 하드웨어적인 방법으로만 가능하다는 설명은 틀린 설명 |
38. 형상 관리의 개념과 절차에 대한 설명으로 틀린 것은?
① 형상 식별은 형상 관리 계획을 근거로 형상 관리의 대상이 무엇인지 식별하는 과정이다.
② 형상 관리를 통해 가시성과 추적성을 보장함으로써 소프트웨어의 생산성과 품질을 높일 수 있다.
③ 형상 통제 과정에서는 형상 목록의 변경 요구를 즉시 수용 및 반영해야 한다.
④ 형상 감사는 형상 관리 계획대로 형상 관리가 진행되고 있는지, 형상 항목의 변경이 요구사항에 맞도록 제대로 이뤄졌는지 등을 살펴보는 활동이다.
| 형상 관리 (SCM) : 소프트웨어의 개발 과정에서 소프트웨어의 변경 사항을 관리하기 위해 개발된 일련의 활동 - 소프트웨어 변경의 원인을 알아내고 제어하며, 적절히 변경되고 있는지 확인하여 해당 담당자에게 통보한다. - 형상 관리는 소프트웨어 개발의 전 단계에 적용되는 활동이며, 유지보수 단계에서도 수행된다. - 형상 관리는 소프트웨어 개발의 전체 비용을 줄이고, 개발 과정의 여러 방해 요인이 최소화되도록 보증하는 것을 목적으로 한다. - 관리 항목에는 소스 코드뿐만 아니라 각종 정의서, 지침서, 분석서 등이 포함된다. - 형상 관리를 통해 가시성과 추적성을 보장함으로써 소프트웨어의 생산성과 품질을 높일 수 있다. - 대표적인 형상 관리 도구 : Git, CVS, Subversion 형상 관리의 중요성 - 지속적인 소프트웨어의 변경 사항을 체계적으로 추적하고 통제할 수 있다. - 제품 소프트웨어에 대한 무절제한 변경을 방지할 수 있다. (불필요한 사용자의 소스 수정 제한) - 제품 소프트웨어에서 발견된 버그나 수정 사항을 추적할 수 있다. - 소프트웨어는 형태가 없어 가시성이 결핍되므로 진행 정도를 확인하기 위한 기준으로 사용될 수 있다. - 소프트웨어의 배포본을 효율적으로 관리할 수 있다. - 소프트웨어를 여러 명의 개발자가 동시에 개발할 수 있다. 형상 관리 기능 형상 식별 : 형상 관리 대상에 이름과 관리 번호를 부여(식별)하고, 계층(Tree) 구조로 구분하여 수정 및 추적이 용이하도록 제어하는 작업 버전 제어 : 소프트웨어 업그레이드나 유지 보수 과정에서 생성된 다른 버전의 형상 항목을 관리하고, 이를 위해 특정 절차와 도구를 결합시키는 작업 형상 통제(변경 관리) : 식별된 형상 항목에 대한 변경 요구를 검토하여 현재의 기준선이 잘 반영될 수 있도록 조정하는 작업 - 변경 요구를 '즉시' 수용하는 것이 아니라, 형상 통제 위원회의 심의를 거쳐 변경의 타당성을 검토한 후 승인된 변경 사항만 반영 형상 감사 : 기준선의 무결성을 평가하기 위해 확인, 검증, 검열 과정을 통해 공식적으로 승인하는 작업 형상 기록(상태 보고) : 형상의 식별, 통제, 감사 작업의 결과를 기록, 관리하고 보고서를 작성하는 작업 대표적인 형상 관리 도구 : Git, CVS, Subversion 등 답: 3번 '즉시' 해야하는 것은 아니다. |
39. 다음 그래프에서 정점 A를 선택하여 깊이 우선 탐색(DFS)으로 운행한 결과는?

① ABECDFG
② ABECFDG
③ ABCDEFG
④ ABEFGCD
| 깊이 우선 탐색 (DFS) 계속 밑으로 내려간다 A → B → E → F → G 다 내려간 다음에 남은 노드 방문 C → D 너비 우선 탐색 (BFS) 인접 노드 먼저 방문 답: 4번 |
40. 분할 정복(Divide and Conquer)에 기반한 알고리즘으로 피봇(pivot)을 사용하며 최악의 경우 n(n-1)/2회의 비교를 수행해야 하는 정렬(Sort)은?
① Selection Sort
② Insert Sort
③ Bubble Sort
④ Quick Sor
| 정렬 삽입 정렬 (Insert Sort) : 이미 정렬된 부분과 비교하여 자기 위치를 찾아 삽입 (2번째 요소부터 시작) 예. 8,5,6,2,4 (1회전) 8,5,6,2,4 → 5,8,6,2,4 : 두 번째 값을 첫 번째 값과 비교하여 5를 첫 번째 자리에 삽입하고 8을 한 칸 뒤로 이동 (2회전) 5,8,6,2,4 → 5,6,8,2,4 : 세 번째 값을 첫 번째, 두 번째 값과 비교하여 6을 8자리에 삽입하고 8을 한칸 뒤로 이동 (3회전) 5,6,8,2,4 → 2,5,6,8,4 : 네 번째 값 2를 처음부터 비교하여 맨 처음에 삽입하고 나머지를 한 칸씩 뒤로 이동 (4회전) 2,5,6,8,4 → 2,4,5,6,8 : 다섯 번째 값 4를 처음부터 비교하여 5자리에 삽입하고 나머지를 한 칸씩 뒤로 이동 선택 정렬 (Selection Sort) : 최솟값을 찾아 맨 앞으로 보냄 예. 8,5,6,2,4 (1회전) 8,5,6,2,4 → 8,5,6,2,4 → 2,5,6,8,4 : 첫 번째부터 마지막 값 중 최소값 2를 찾아 첫 번째 값 8과 위치를 교환 (2회전) 2,5,6,8,4 → 2,5,6,8,4 → 2,4,6,8,5 : 두 번째부터 마지막 값 중 최소값 4를 찾아 두 번째 값 5와 위치를 교환 (3회전) 2,4,6,8,5 → 2,4,6,8,5 → 2,4,5,8,6 : 세 번째부터 마지막 값 중 최소값 5를 찾아 세 번째 값 6과 위치를 교환 (4회전) 2,4,5,8,6 → 2,4,5,8,6 → 2,4,5,6,8 : 네 번째부터 마지막 값 중 최소값 6을 찾아 네 번째 값 8과 위치를 교환 버블 정렬 (Bubble Sort) : 인접한 두 원소를 비교하여 교환. (가장 큰 값이 맨 뒤로 밀려남) 예. 8,5,6,2,4 (1회전) 8,5,6,2,4 → 5,6,8,2,4 → 5,6,2,8,4 → 5,6,2,4,8 (2회전) 5,6,2,4,8 → 5,2,6,4,8 → 5,2,4,6,8 (3회전) 2,5,4,6,8 → 2,4,5,6,8 (4회전) 2,4,5,6,8 퀵 정렬 (Quick Sor) 레코드의 많은 자료 이동을 없애고 하나의 파일을 부분적으로 나누어 가면서 정렬하는 방법으로 키를 기준으로 작은 값은 왼쪽에, 큰 값은 오른쪽 서브파일로 분해시키는 방식으로 정렬 - 분할(Divide)과 정복(Conquer)을 통해 자료를 정렬한다. - 평균 수행 시간 복잡도는 O(nlog2n)이고, 최악의 수행 시간 복잡도는 O(n2)이다. - 피봇(Pivot) : 정렬의 기준이 되는 중간값을 의미, 이 피봇을 기준으로 작은 값은 왼쪽, 큰 값은 오른쪽으로 모으는 과정을 반복 힙 정렬 (Heap Sort) 힙 정렬은 전이진 트리를 이용한 정렬 방식 - 구성된 전이진 트리를 Heap Tree로 변환하여 정렬 - 평균과 최악 모두 시간 복잡도는 O(nolg2n) 2-Way 합병 정렬 (Merge Sort) 이미 정렬되어 있는 두 개의 파일을 한 개의 파일로 합병하는 정렬 방식 - 평균과 최악 모두 시간 복잡도는 O(nlog2n) 이진 검색(이분 검색, Binary Search) 전체 파일을 두 개의 서브파일로 분리해 가면서 Key 레코드를 검색하는 방식 해싱 함수 (Hashing Function) - 제산법 : 레코드 키를 해시표의 크기보다 큰 수 중에서 가장 작은 소수로 나눈 나머지를 홈 주소로 삼는 방식 - 제곱법 : 레코드 키 값을 제곱한 후 그 중간 부분의 값을 홈 주소로 삼는 방식 - 폴딩법 : 레코드 키 값을 여러 부분으로 나눈 후 각 부분의 값을 더하거나 XOR한 값을 홈 주소로 삼는 방식 - 기수변환법 : 키 숫자의 진수를 다른 진수로 변환시켜 주소 크기를 초과한 높은 자릿수는 절단하고, 이를 다시 주소 범위에 맞게 조정하는 방법 - 대수적 코딩법 : 키 값을 이루고 있는 각 자리의 비트 수를 한 다항식의 계수로 간주하고, 이 다항식을 해시표의 크기에 의해 정의된 다항식으로 나누어 얻은 나머지 다항식의 계수를 홈 주소로 삼는 방식 - 숫자 분석법 : 키 값을 이루는 숫자의 분포를 분석하여 비교적 고른 자리를 필요한 만큼 택해서 홈 주소로 삼는 방식 - 무작위법 : 난수를 발생시켜 나온 값을 홈 주소로 삼는 방식 답: 4번 |
| 정보처리기사 필기 기출문제 | |||||
| 24년 3회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 24년 2회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 24년 1회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 23년 3회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 23년 2회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
| 23년 1회 | 1과목 | 2과목 | 3과목 | 4과목 | 5과목 |
'자격증 요약 > 정보처리기사' 카테고리의 다른 글
| [24년 1회 2과목] 정보처리기사 필기 문제 풀이 (1) | 2026.01.19 |
|---|---|
| [24년 2회 2과목] 정보처리기사 필기 문제 풀이 (0) | 2026.01.19 |
| [23년 1회 1과목] 정보처리기사 필기 문제 풀이 (0) | 2026.01.14 |
| [23년 2회 1과목] 정보처리기사 필기 문제 풀이 (2) | 2026.01.14 |
| [23년 3회 1과목] 정보처리기사 필기 문제 풀이 (1) | 2026.01.13 |