
1. 다음은 파일 구조와 관련된 설명이다.설명을 읽고 괄호 안에 들어갈 가장 알맞은 용어를 작성하시오.
- 데이터베이스의 물리 설계 시,레코드에 접근하는 방법은 순차 접근 방법, [ ]방법,해싱 방법 등이 있다.
- 이 중[ ]방법은 레코드의 키 값과 포인터를 쌍으로 묶어 저장하며 검색 시 키 값을 기준으로 빠르게 탐색할 수 있도록 설계되어 있다.
- 이 방식은 검색 속도가 빠르며<키 값,포인터>쌍으로 구성된 자료 구조를 사용하여 해당 키가 가리키는 주소를 통해 원하는 레코드를 직접 찾을 수 있다.

| 답: 인덱스 or 색인 인덱스(Index): 검색 속도를 높이기 위해 <키 값, 포인터> 쌍으로 구성한 보조 자료 구조. (책의 색인) 해싱(Hashing): 해시 함수를 이용해 키 값을 주소로 직접 변환하여 접근하는 방식입니다. 검색 속도가 가장 빠름. JSON: 데이터 객체를 속성(Key): 값(Value) 쌍으로 표현하는 텍스트 기반의 데이터 포맷입니다. 주로 네트워크에서 데이터를 주고받을 때 사용. ※ JSON vs 인덱스: 둘 다 키-값 쌍이지만, JSON은 데이터 교환용 '형식'이고, 인덱스는 DB 검색용 '지표'입니다. |
2. 다음은 데이터베이스 릴레이션의 구성 요소 중 하나에 대한 설명이다.설명을 읽고 보기에서 알맞은 기호를 골라 작성하시오.
- 릴레이션(Relation)에서 열(Column)을 의미하며 데이터 항목의 속성(Attribute)또는 특성을 나타낸다.
- 각 열은 고유한 이름을 가지며 특정 도메인(Domain)에서 정의된 값을 갖는다.
- 예를 들어"학생"릴레이션에서 학번,이름,전공 등은 각각 하나의 열이며 이 열들은 학생의 고유한 속성을 나타낸다.
- 이 개념은 파일 구조에서의 필드(Field)에 해당하며 릴레이션에서 행(Row, Tuple)의 구성 요소가 된다.
[보기] ㄱ. Cardinality ㄴ. Domain ㄷ. Attribute ㅁ. Degree ㅂ. Schema ㅅ. Tuple
| 답: ㄷ. Attribute 스키마 (Schema) - 데이터베이스의 구조(Structure)와 제약 조건에 관한 전반적인 명세를 정의한 '틀' - 속성, 개체, 관계 등을 정의. → '구조적 정의', '데이터베이스의 뼈대' 속성 (Attribute) - 데이터베이스를 구성하는 가장 작은 논리적 단위이며, 파일 구조상의 '항목(Field)' 또는 '열(Column)' - 개체의 특성을 기술합니다. 튜플 (Tuple) - 테이블 내의 한 행(Row)을 의미하며, 하나의 레코드(Record)와 같음 - 속성들의 모임으로 구성됩니다. 차수 (Degree) - 하나의 릴레이션(테이블) 안에 있는 속성(열)의 전체 개수 - '세로 줄이 몇 개인가' 카디널리티 (Cardinality) - 하나의 릴레이션(테이블) 안에 있는 튜플(행)의 전체 개수 - '가로 줄이 몇 개인가' 인스턴스 (Instance) - 특정 시점에 데이터베이스에 들어있는 실제 데이터 값들의 집합 - 스키마는 잘 변하지 않지만, 인스턴스는 데이터의 삽입/삭제에 따라 수시로 변함 도메인 (Domain) - 하나의 속성(Attribute)이 취할 수 있는 동일한 유형의 원자값(Atomic Value)들의 집합 - 데이터의 무결성을 유지하기 위해 특정 속성에 들어갈 값의 범위를 제한하는 '규약' 역할 - 예. '성별' 속성의 도메인은 {남, 여}입니다. (이 외의 값은 입력 불가), '점수' 속성의 도메인이 0~100 사이의 정수라면, 105점은 입력될 수 없습니다. |
3. 다음은 정보보안 관련 문제이다. 아래 내용을 보고 알맞는 단어를 작성하시오.
- 원격 접속과 관련된 보안 프로토콜이며 암호화된 통신을 제공하는 보안 접속용 프로토콜이다.
- 공개키 기반의 인증 방식을 사용하며 암호화된 데이터 전송을 지원한다.
- 주로 원격 서버에 안전하게 접속할 때 사용되며 기본 포트 번호는22번이다.
- Telnet의 보안 취약점을 보완한 대안으로 널리 사용된다.
| 답: SSH SSH (Secure SHell, 시큐어 셀) SSH는 다른 컴퓨터에 로그인, 원격 명령 실행, 파일 복사 등을 수행할 수 있도록 다양한 기능을 지원하는 프로토콜 또는 이를 이용한 응용 프로그램 - 데이터 암호화와 강력한 인증 방법으로 보안성이 낮은 네트워크에서도 안전하게 통신할 수 있다. - 키(key)를 통한 인증 방법을 사용하려면 사전에 클라이언트의 공개키를 서버에 등록해야 한다. - 기본적으로 22번 포트를 사용한다. HTTPS : 웹 브라우저 보안, SSL/TLS - 443 포트 - HTTP에 SSL/TLS를 더한 보안 프로토콜 SFTP : SSH 기반, 안전한 FTP - 22 포트 - SSH의 보안 기능을 활용한 파일 전송 SNMP : TCP/IP 네트워크 관리 - 161/162 포트 - 네트워크 장비를 관리/모니터링하는 프로토콜 IPsec : VPN, 가상 사설망, 망 계층 보안 - IP 계층(3계층)에서 암호화 및 인증 제공 SSL/TLS : 인증서, 데이터 기밀성 - 응용 계층과 전송 계층 사이의 보안 계층 |
4. 스케줄링 알고리즘에 관한 다음 설명을 읽고(1)과(2)에 알맞은 스케줄링 알고리즘의 명칭을 각각 쓰시오.
- (1) CPU burst시간이 짧은 프로세스를 우선적으로 처리하는 스케줄링 방식이다."Shortest Next CPU Burst"라고도 불리며 선점형 또는 비선점형으로 구현될 수 있다.
- (2) 위의 스케줄링 방식을 선점형으로 구현한 형태로 실행 중인 프로세스보다 더 짧은burst시간을 가진 프로세스가 도착하면 현재 CPU를 선점한다.
| 답: (1) SJF (Shortest Job First) (2) SRT (Shortest Remaining Time) 비선점 (Non-Preemptive) 스케줄링 - 이미 할당된 CPU를 다른 프로세스가 강제로 빼앗을 수 없는 방식 - 응답 시간 예측이 용이하며, 일괄 처리 방식에 적합 - 종류: FCFS(First-Come First-Served), SJF(Shortest Job First), HRN(Highest Response-ratio Next), 우선순위, 기한부 등 선점 (Preemptive) 스케줄링 - 하나의 프로세스가 CPU를 할당받아 실행 중이더라도 우선순위가 높은 다른 프로세스가 CPU를 강제로 빼앗을 수 있는 방식 - 빠른 응답을 요구하는 대화형 시분할 시스템에 적합 - 종류: SRT(Shortest Remaining Time), RR(Round Robin), 다단계 큐, 다단계 피드백 큐 등 |
5. 다음은 Java의 문제이다. 아래 코드를 보고 알맞는 출력값을 작성하시오.
public class Main {
public static void change(String[] data, String s) {
data[0] = s;
s = "Z";
}
public static void main(String[] args) {
String data[] = { "A" };
String s = "B";
change(data, s);
System.out.print(data[0] + s);
}
}| 답: BB public class Main { public static void change(String[] data, String s) { → main에서 보낸 data 주소와 "B"라는 값을 받았다. data[0] = s; → 전달받은 data 주소로 가서 data[0]을 s로 바꿔라 → 메인에 있는 data[0]도 s값으로 바꿈 → s값은 "B"를 전달 받아왔으므로, 메인에 있는 data[0]의 값은 A에서 B로 바뀐다. s = "Z"; → change 함수 안에 있는 s라는 변수에 "Z"를 넣어라. → 이건 change 함수 안에서만 쓰는 복사본 s로, main에 있는 원래 s와는 상관 없음 → 절차가 끝났으므로 다음 문장으로 이동 = System.out.print(data[0] + s); public static void main(String[] args) { String data[] = { "A" }; String data[] = { "A" }; : String[] 배열을 만들고 첫 번째 칸(data[0])에 "A"를 넣어라. → data라는 변수는 실제 "A"가 든 주소를 가리키고 있음. String s = "B"; String s = "B"; : s라는 일반 변수에 "B"라는 글자 담음 change(data, s); → 위에서 만든 배열 data 와 문자열 s를 가지고 change라는 함수(메소드)로 가라 → data 주소값을 넘겨주는 것. s는 "B"값 자체를 복사해서 넘겨줌 System.out.print(data[0] + s); → data[0]은 "B"가 되었으므로 B가 출력 → s의 경우에는 main함수에서 가져오는 것이므로 "B". B가 출력 (change에서 변경된 Z값을 가져오는 것이 아니다.) 그러므로 BB가 출력 |
6. 다음은 IP주소와 서브넷 마스크에 관한 문제이다. 주어진 정보를 참고하여 괄호 안에 들어갈 알맞은 값을 쓰시오.
호스트의IP주소가223.13.234.132이고서브넷 마스크가255.255.255.192일 때 다음 물음에 답하시오.
- 이 호스트가 속한 네트워크 주소는223.13.234.(①)이다.
- 이 네트워크에서 사용 가능한 호스트 수는(②)개이다.
- (단,네트워크 주소와 브로드캐스트 주소는 제외한다.)
| 답: ① 128 ② 62 |
7. 다음은 디자인 패턴에 관한 문제이다. 아래 내용을 보고 알맞는 단어를 작성하시오.
- 어떤 객체에 대한 접근을 제어하거나 추가적인 기능을 부여하기 위해해당 객체의 대리 객체를 사용하는 방식의 디자인 패턴이다. 실제 객체에 대한 접근 전에 필요한 작업을 수행할 수 있으며 실제 객체의 생성을 지연시켜 메모리와 자원을 절약할 수 있다. 또한,실제 객체를 감추어 정보은닉을 강화할 수 있다는 장점이 있다.
| 답: Proxy |
8. 다음은 웹 데이터 교환 방식에 관한 문제이다. 아래 설명을 읽고괄호 안에 들어갈 알맞은 용어를 작성하시오.
- ( )은/는 웹 페이지 전체를 다시 불러오지 않고JavaScript와XML(또는JSON)을 이용하여 일부 콘텐츠만 비동기적으로 갱신할 수 있 는 기술이다.
- ( )은/는HTML만으로는 구현하기 어려운 동적인 기능들을 가능하게 하여 사용자가 웹 페이지와 보다 자유롭게 상호작용할 수 있도 록 해주는 웹 개발 기법이다.
| 답: AJAX AJAX - 비동기적(Asynchronous): 서버에 데이터를 요청하고 응답이 올 때까지 화면이 멈추지 않고 다른 작업을 할 수 있다 - 일부 콘텐츠만 갱신: 전체 페이지를 새로고침(F5) 하지 않고, 좋아요 숫자나 댓글창만 슥 바뀌는 기술이 바로 AJAX입니다. JSON - AJAX에서 데이터를 주고받을 때 쓰는 가벼운 텍스트 형식 - 자바스크립트 객체 형태, XML 대체 (※AJAX의 이름에는 XML이 들어있지만, 실제 요즘 웹에서는 용량이 가벼운 JSON을 훨씬 더 많이 씁니다. 문제에서 "최근에는 XML 대신 이것을 주로 사용한다"라고 하면 정답은 JSON입니다.) XML - 데이터를 정의하는 태그 기반 언어 (AJAX의 'X'가 이것) - 사용자 정의 태그, 확장성 REST - 웹의 장점을 최대한 활용하는 아키텍처 스타일 - HTTP URI, 자원(Resource) 중심 SOAP - HTTP 등을 이용해 XML 기반 메시지를 교환하는 프로토콜 - 봉투(Envelope) 구조, 오버헤드 큼 |
9. 다음은 Java 언어의 문제이다. 아래 코드를 보고 알맞는 출력값을 작성하시오.
public class Main {
static interface F {
int apply(int x) throws Exception;
}
public static int run(F f) {
try {
return f.apply(3);
} catch (Exception e) {
return 7;
}
}
public static void main(String[] args) {
F f = (x) -> {
if (x > 2) {
throw new Exception();
}
return x * 2;
};
System.out.print(
run(f) +
run((int n) -> n + 9)
);
}
}| 답: 19 public class Main { static interface F { → 인터페이스(intergace)는 이런 모양(F)으로 만들거야라고 정의 int apply(int x) throws Exception; int apply(int x) : int(정수)를 주면(int apply), 계산해서 다시 int(정수)를 준다(int x). throws Exception; : 이 기능 안에서 에러가 발생하면, throw new Exception() 으로 간다는 뜻 → 실기에서 throws, throw가 나오면 정상적인 계산 결과인지, 에러가 나서 catch문이 나올 것인지를 묻는 문제 public static int run(F f) { → 에러가 났을 때 대신 실행해준다. → run(F f) : f 라는 주문서 가져오면 대신 실행 → f 자리에 run(f), run((int n) -> n + 9) 의 값이 들어가서, 아래에 계산이 되는 것 try { return f.apply(3); → 가져온 기능에 숫자 3을 넣어서 결과를 뽑아내봐라 → 3은 2보다 크다. 그러므로 에러가 실행된다. → n+9에서 n에 3의 값을 넣는다. } catch (Exception e) { return 7; → f.appty(3)을 실행했는데도 에러가 나면, 7값으로 반환해라. → 에러가 실행되므로 7값이 반환된다. → n+9에서는 에러가 발생하지 않으므로 무시 public static void main(String[] args) { F f = (x) -> { → F f 를 정의하겠다. (x) : 숫자를 하나 받을건데, 그 숫자는 x라고 부르겠다. -> { : x 값을 가지고 중괄호{} 안의 일을 시킬거다. if (x > 2) { throw new Exception(); → 만약 받은 숫자 x가 2보다 크다면, 에러이므로 에러문을 실행한다. return x * 2; → 에러가 안 났다면, x값에 2를 곱해서 돌려준다. → 에러가 났다면, 실행되지 않는다. System.out.print( run(f) + → run(f) : 여기서 위(public static int run(F f) {)로 올라가서 실행된다. (※숫자가 2보다 크면 에러로 반환해라) → 7이 된다. run((int n) -> n + 9) run((int n) : 숫자 n 하나를 받는다. -> n + 9) : 받은 숫자에 9를 더한다. → 해당 처리방법을 가지고 위(public static int run(F f) {)로 이동한다. → n + 9 에서 n에는 3값을 가지고 돌아온다. 즉, 3+9 = 12값이 된다. 그러므로 7+12 = 19가 출력된다. |
10. 다음은 Java 언어의 문제이다. 아래 코드를 보고 알맞는 출력값을 작성하시오.
public class Main {
public static class Parent {
public int x(int i) {
return i + 2;
}
public static String id() {
return "P";
}
}
public static class Child extends Parent {
public int x(int i) {
return i + 3;
}
public String x(String s) {
return s + "R";
}
public static String id() {
return "C";
}
}
public static void main(String[] args) {
Parent ref = new Child();
System.out.println(ref.x(2) + ref.id());
}
}답: 5P Parnet ref = new Child(); Child 를 수행할 때, Parnet 의 변수도 사용할 수 있다. ref.x(2) → Public int x(int i) 2는 정수이므로, 동일한 변수형태를 가진 곳으로 가서 계산을 수행한다. 그러므로 return i + 3 = 5 값이 리턴한다. ※좀 더 정확히는, Parent에 x(int)가 있는지 확인하고, 실제 실행은 Child의 x(int)에서 한다. → Child에 x(int)가 없었다면, 부모의 x(int)를 실행했다. ref.id() → public static String id() → public static string id() id()와 동일한 형태를 찾아갔다가, static 가 있으므로 parnet 를 호출해서 수행한다. 그러므로 return "P" = P 값이 리턴한다. 최종적으로 5P가 출력된다. (※ln 이 붙어있으므로 출력후 엔터쳐진다) |
11. 다음 아래 제어 흐름 그래프가 분기 커버리지를 만족하기 위한 테스팅 순서를 쓰시오.

| 답: 1234561,124567 or 1234567,124561 분기 커버리지 : 프로그램 내의 모든 조건문의 결과가 True인 경우와 False인 경우를 최소 한번씩은 실행하도록 테스트 경로를 구성하는 것 제어 흐름 그래프에 결정 지점(다이아몬드 박스)이 2번, 6번이므로 두 곳에서 YES와 NO를 모두 가보는 순서로 동작한다. |
12. 다음은 C언어의 문제이다. 아래 코드를 보고 알맞는 출력값을 작성하시오.
#include <stdio.h>
#define SIZE 3
typedef struct {
int a[SIZE];
int front;
int rear;
} Queue;
void enq(Queue* q, int val) {
q->a[q->rear] = val;
q->rear = (q->rear + 1) % SIZE;
}
int deq(Queue* q) {
int val = q->a[q->front];
q->front = (q->front + 1) % SIZE;
return val;
}
int main() {
Queue q = {{0}, 0, 0};
enq(&q, 1);
enq(&q, 2);
deq(&q);
enq(&q, 3);
int first = deq(&q);
int second = deq(&q);
printf("%d 그리고 %d", first, second);
return 0;
}| 답: 2 그리고 3 #include <stdio.h> #define SIZE 3 typedef struct { int a[SIZE]; int front; int rear; → 각 값을 설정한다. ※큐(Queue)의 기본 규칙 : FIFO (선입선출) - front : 데이터가 나가는 문(출구) - rear : 데이터가 들어오는 문(입구) } Queue; void enq(Queue* q, int val) { q->a[q->rear] = val; q->rear = (q->rear + 1) % SIZE; → 원형 큐라는 것을 알 수 있는 근거 → enq(&q,1), enq(&q,2) 를 계산할 때 이곳으로 와서 계산된다. enq(Queue* q : 여기서 q는 전달받은 &q(주소)를 저장하고 있다. q->rear : 주소 q를 찾아가서 그 안에 있는 rear라는 칸에 적힌 숫자를 읽어라 → &q를 주면, enq함수가 그걸 q라는 이름으로 받아서 q->rear를 조작한다. int deq(Queue* q) { int val = q->a[q->front]; q->front = (q->front + 1) % SIZE; return val; int val = q->a[q->front] : q의 출구 번호(front)가 가리키는 칸(a[ ])에 가서, 거기 있는 값을 임시 값(val)에 넣어라 q->front = (q->front + 1) % SIZE; : 값을 꺼냈으니, 출구 번호(front)를 다음 칸으로 옮겨라. (끝까지 갔으면 처음으로 돌아와라) return val; : 임시 값에 있는 값을 리턴해서 가져가라  int main() { Queue q = {{0}, 0, 0}; → 초기 상태 설정 : q = {0, 0, 0} / front = 0, rear = 0 enq(&q, 1); enq(&q, 1) : q주소에 1을 넣는다. → q->a[q->rear] = val; : q -> a[0] = 1 → q->rear = (q->rear + 1) % SIZE; : rear = (0 + 1) % 3 = 1 enq(&q, 2); → q -> a[1] = 2 → rear = (1 + 1) % 3 = 2 ※&q : enq함수를 실행할 때마다 'q -> rear'이란 내부 변수 값이 계속 변하기 때문에, a[0] 다음인 a[1]이 호출되는 것 - 첫 번째 enq(&q,1) 실행 → rear은 현재 0, a[0]에 1을 넣음 → rear은 한 칸 옆인 1로 옮겨감 - 두 번째 enq(&q,2) 실행 → rear은 현재 1, a[1]에 2을 넣음 → rear은 한 칸 옆인 2로 옮겨감 deq(&q); int val = q->a[q->front]; : q->a[0] = 1 (enq로 1이 들어왔으니까), 1값을 임시 값(val)에 넣는다. q->front = (q->front + 1) % SIZE; : (0 + 1) % 3 = 1, 1값을 q->front 에 넣는다. return val; : 임시 값(val)에 들어간 1을 리턴한다. (※main 함수에서 int x = deq(&q)처럼 넣은 게 아니라, 그냥 출구로 값을 보낸 것이기 때문에 1 값은 없어진다.) (※데이터 1은 메모리 상에는 남아있을 수 있지만, front라는 출구 위치가 이미 1번 칸으로 이동했기 때문에, deq를 호출하면 그 뒷자리인 2부터 나오게 된다.) enq(&q, 3); → q -> a[2] = 3 → rear = (2 + 1) % 3 = 0 (※0으로 바뀌기 때문에, 다시 초기로 돌아간다) int first = deq(&q); deq(&q) : q->front가 1이므로 a[1]에 있는 값 2를 꺼내어 first 변수에 담는다. front 는 다음 칸으로 옮긴다. (1 + 1) % 3 = 2 int second = deq(&q); deq(&q) : q->front가 2이므로 a[2]에 있는 값 3을 꺼내어 second 변수에 담는다. front 는 다음 칸으로 옮긴다. (2 + 1) % 3 = 0 printf("%d 그리고 %d", first, second); first에 저장된 2와 second에 저장된 3이 서식에 맞춰 출력된다. 그러므로 출력내용 : 2 그리고 3 ※참고 q->rear는 그 자체로 q[0], q[1]이 되는 것이 아니라, q->a[ ]라는 이름의 선반 중 몇 번 칸을 가리킬지 정하는 손가락과 같습니다. - rear 값이 0이면 → q->a[0] 칸에 데이터를 넣습니다. - rear 값이 1이면 → q->a[1] 칸에 데이터를 넣습니다. - rear 값이 2이면 → q->a[2] 칸에 데이터를 넣습니다. |
13. 라운드 로빈(RR)방식을 이용하고, 아래 내용을 참고하여 평균 대기 시간을 구하시오.
- 운영체제에서 라운드로빈(Round Robin, RR)스케줄링은 각 프로세스에 동일한 시간 할당량(타임 퀀텀)을 순차적으로 부여하며 CPU를 할당하는 방식이다.
- 다음은4개의 프로세스가 서로 다른 시간에 도착하며 각기 다른 실행 시간을 가지는 상황이다.이때 시간 할당량은 4ms이고 컨텍스트 스위칭 시간은 무시한다고 가정한다.
- 아래 정보를 바탕으로 라운드로빈(RR)방식으로CPU스케줄링을 수행할 경우 모든 프로세스의 평균 대기시간(Average Waiting Time)은 얼마인가?

| 답: 11.75ms 시간 할당량 : 4ms 시간의 흐름에 따라 간트 차트 그리기 0 ~ 4ms : 0초에 P1만 있으므로 바로 시작, 4ms 실행 후, 실행시간 8ms에서 4ms가 남음 4 ~ 8ms : 순차적으로 부여하므로 P2 시작, 4ms 실행 후, 실행시간 4ms에서 0ms가 남음 = P2은 종료 8 ~ 12ms : 큐 다음 순서인 P3 시작, 4ms 실행 후, 실행시간 9ms에서 5ms가 남음 12 ~ 16ms : 큐 다음 순서인 P4 시작, 4ms 실행 후, 실행시간 5ms에서 1ms가 남음 16 ~ 20ms : 한 바퀴 돌아서 다시 P1 시작, 4ms 실행 후, 실행시간 4ms에서 0ms가 남음 = P1 종료 20 ~ 24ms : 큐 다음 순서인 P3 시작, 4ms 실행 후, 실행시간 5ms에서 1ms가 남음 24 ~ 25ms : 큐 다음 순서인 P4 시작, 남은 실행시간 1ms만 실행하고 종료 = P4 종료 25 ~ 26ms : 큐 다음 순서인 P3 시작, 남은 실행시간 1ms만 실행하고 종료 = P3 종료 간트차트 정리  각 프로세스의 종료 시간 및 대기 시간 계산 [종료시간 - 도착시간 - 실행시간] P1: 20(종료) - 0(도착) - 8(실행) = 12ms P2: 8(종료) - 1(도착) - 4(실행) = 3ms P3: 26(종료) - 2(도착) - 9(실행) = 15ms P4: 25(종료) - 3(도착) - 5(실행) = 17ms 평균 대기 시간 [각 큐별 대기시간/시간 할당량] (12+3+15+17)/4 = 11.75 |
14. 다음은 C언어의 문제이다. 아래 코드를 보고 알맞는 출력값을 작성하시오.
#include <stdio.h>
struct dat {
int x;
int y;
};
int main() {
struct dat a[] = {{1,2}, {3,4}, {5,6}};
struct dat* ptr = a;
struct dat** pptr = &ptr;
(*pptr)[1] = (*pptr)[2];
printf("%d 그리고 %d", a[1].x, a[1].y);
return 0;
}| 답: 5 그리고 6 #include <stdio.h> struct dat { int x; int y; → 배열의 초기 상태 정의  int main() { struct dat a[] = {{1,2}, {3,4}, {5,6}};  struct dat* ptr = a; dat* ptr = a : ptr이라는 포인터가 배열의 시작점 a[0]을 가리킴 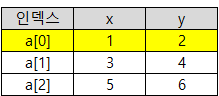 struct dat** pptr = &ptr; dat** pptr = &ptr; : pptr은 ptr이라는 포인터 변수의 주소를 가리킴. (포인터를 가리키는 포인터) (*pptr)[1] = (*pptr)[2]; (*pptr) : ptr을 가리키고 있으므로 (*pptr) = ptr 과 같은 놈 (*pptr)[1] = (*pptr)[2]; : ptr[1] = ptr[2]; 같은 말이다. → ptr은 현재 배열 a[0]를 가리키고 있다. → ptr[1]은 a[1]을 의미하고, ptr[2]는 a[2[를 의미한다. → 즉, a[2]의 값을 a[1]에 넣으라는 뜻  printf("%d 그리고 %d", a[1].x, a[1].y); a[1].x : a[1]의 x값은 5 a[1].y) : a[1]의 y값은 6 그러므로 출력값은 5 그리고 6 |
15. 다음은 Java 언어의 문제이다. 아래 코드를 보고 알맞는 출력값을 작성하시오.
public class Main {
public static class BO {
public int v;
public BO(int v) {
this.v = v;
}
}
public static void main(String[] args) {
BO a = new BO(1);
BO b = new BO(2);
BO c = new BO(3);
BO[] arr = { a, b, c };
BO t = arr[0];
arr[0] = arr[2];
arr[2] = t;
arr[1].v = arr[0].v;
System.out.println(a.v + "a" + b.v + "b" + c.v);
}
}| 답: 1a3b3 public class Main { public static class BO { public int v; public BO(int v) { this.v = v; } } public static void main(String[] args) { BO a = new BO(1); new BO(1) 은 생성자를 찾아간다. (public static class BO {) public BO(int v) { : (int v)에 배달된 1을 받는다. 이때 int v는 외부에서 들어온 값 this.v : this.v 는 내(BO)가 진자로 가지고 있는 값. this.v = v; : 그러므로 외부에서 들어온 값을 나(BO)에게 저장하겠다. → BO a의 a는 BO(1) 의 1을 가리키고 있다. BO b = new BO(2); → b는 2를 가리키고 있다. BO c = new BO(3); → c는 3을 가리키고 있다. BO[] arr = { a, b, c }; → a,b,c가 가리키는 객체들로 배열을 만든다. 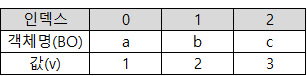 BO t = arr[0]; → t 는 이제부터 arr[0]이 가리키던 것과 같은 것을 가리킨다. → 즉, t는 객체명 a 와 값 1을 가리키게 된다.  arr[0] = arr[2]; → arr[0] 은 이제부터 객체명 c를 가리키고, 값 3을 가리킨다. (※arr[0]에 있는 값이 바뀌는 것이 아니라, arr[0]이 가리키는 것이 arr[2]와 같아진 것)  arr[2] = t; → arr[2] 은 이제부터 t 가 가리키는 것을 가리키게 된다. → t 는 객체명 a와 값 1을 가리키고 있었으므로, 이제부터 arr[2]도 가리키게 된다. 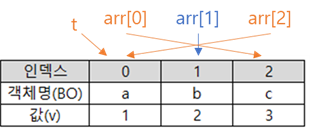 arr[1].v = arr[0].v; arr[1].v : arr[1] 은 객체 b, 값(v) 2 를 가리키고 있다. arr[0].v : arr[0] 은 객체 c, 값(v) 3 을 가리키고 있다. arr[1].v = arr[0].v; : 즉, arr[1]의 값(v)에 arr[0]의 값(v)을 넣어라  System.out.println(a.v + "a" + b.v + "b" + c.v); a.v : 1 값을 가지고 있음 "a" : 문자 a b.v : 3 값을 가지고 있음 "b" : 문자 b c.v : 3 값을 가지고 있음 (※객체가 가지고 있는 값은 b말고는 변화된 적이 없음.) 그러므로 1a3b3 이 된다. |
16. 다음은 C언어의 문제이다. 아래 코드를 보고 알맞는 출력값을 작성하시오.
#include <stdio.h>
#include <stdlib.h>
struct node {
int p;
struct node* n;
};
int main() {
struct node a = {1, NULL};
struct node b = {2, NULL};
struct node c = {3, NULL};
a.n = &b;
b.n = &c;
c.n = NULL;
c.n = &a;
a.n = &b;
b.n = NULL;
struct node* head = &c;
printf("%d%d%d",
head->p,
head->n->p,
head->n->n->p);
return 0;
}| 답: 312 (공백없이) #include <stdio.h> #include <stdlib.h> struct node { int p; struct node* n; → 노드의 구성을 정의  int main() { struct node a = {1, NULL}; struct node b = {2, NULL}; struct node c = {3, NULL}; → 메모리에 3개의 노드가 만들어진다.  a.n = &b; → a.n(node*n) 은 b주소를 가리킨다. b.n = &c; → b.n(node*n) 은 c주소를 가리킨다. c.n = NULL; → c.n(node*n) 은 NULL을 가리킨다.  c.n = &a; a.n = &b; b.n = NULL; struct node* head = &c; → 노드의 시작점을 c의 주소로 정하겠다. 즉, head란 이름표는 c를 보고 있다. struct node* : node 구조체를 가리키는 포인터(리모컨) head : 포인터(리모컨)의 이름 &c : 노드 c가 있는 주소를 가리켜라.  printf("%d%d%d", head->p, → (파란색) p값을 가리키니까 3 head->n->p, → (초록색) n->p값을 가리키니까 1 head->n->n->p); → (초록색) n->n->p값을 가리키니까 2  그러므로 312 가 된다. (공백없이) |
17. 다음은 Pyhon 언어의 문제이다. 아래 코드를 보고 알맞는 출력값을 작성하시오.
lst = [1, 2, 3]
dst = {i: i * 2 for i in lst}
s = set(dst.values())
lst[0] = 99
dst[2] = 7
s.add(99)
print(len(s & set(dst.values())))| 답: 2 lst = [1, 2, 3] → 리스트가 만들어진다. dst = {i: i * 2 for i in lst} 딕셔너리 컴프리헨션 : 반복문을 한 줄로 줄여 쓴 것 for i in lst : lst에 있는 값을 i 에 넣어라 (※키:값 형태로 딕셔너리에 들어간다.) i: i * 2 : i는 i*2를 해라 dst = 나온 값을 dst에 넣어라 → 1이 들어오면 1:1*2 → {1:2} → 2이 들어오면 2:2*2 → {1:2 , 2:4} → 3이 들어오면 3:2*2 → {1:2 , 2:4, 3:6} s = set(dst.values()) dst.values() : 딕셔너리에서 값(values)만 가져와라 → {1:2 , 2:4, 3:6} → [2, 4, 6] 이 된다 set(dst.values()) : 중복을 허용하지 않는 세트(주머니)로 만든다. → s = {2, 4, 6} 이 된다. lst[0] = 99 → lst의 첫 번째 값을 바꾼다. → lst = [1, 2, 3] → lst = [99, 2 ,3] (※lst와 dst는 다른, 독립적인 딕셔너리이므로 lst를 바꿔도 dst는 안 바뀐다.) dst[2] = 7 → dst에서 키가 2인 요소의 값을 7로 바꾼다. → dst = {1:2 , 2:4, 3:6} → dst = {1:2 , 2:7, 3:6} s.add(99) → s에서 99값을 추가(add)해라. → s = {2, 4, 6} → s = {2, 4, 6, 99} print(len(s & set(dst.values()))) set(dst.values()) : dst의 값(values)은 현재 2,7,6 → 이걸 세트로 만들면 {2,6,7} s : s의 값은 현재 [2,4,6,99] s & set(dst.values()) : 교집합 → {2,4,6,99} & {2,6,7} → 공통된 요소는 2, 6 len(s & set(dst.values())) : 길이(len) 측정 → 2,6이므로 길이는 2 그러므로 2 ※ [ ] : 리스트, 순서가 있고 값을 마음대로 바꿀 수 있음 ※ { } : 딕셔너리, '키:값' 쌍으로 저장. 키를 알면 값을 바로 찾음 ※ { } : 세트, 순서가 없고, 중복을 절대 허용 안 함 ※ ( ) : 튜플, 순서가 있지만, 한 번 정하면 절대 못 바꿈 |
18. 다음은 C언어의 문제이다. 아래 코드를 보고 알맞는 출력값을 작성하시오.
#include <stdio.h>
#include <stdlib.h>
struct node {
char c;
struct node* p;
};
struct node* func(char* s) {
struct node* h = NULL;
struct node* n;
while (*s) {
n = malloc(sizeof(struct node));
n->c = *s++;
n->p = h;
h = n;
}
return h;
}
int main() {
struct node* n = func("BEST");
while (n) {
putchar(n->c);
struct node* t = n;
n = n->p;
free(t);
}
return 0;
}| 답: TSEB #include <stdio.h> #include <stdlib.h> struct node { char c; struct node* p; → 노드(node)의 형태 정의  struct node* func(char* s) { → main 함수에서 'struct node* n = func("BEST")'의 "BEST"값을 받는다. struct node* h = NULL; → node* h 에 NULL 값을 넣는다. struct node* n; → node* n : 앞으로 노드를 만들 때마다 임시 리모컨 n 을 만들겠다. → struct node* n = func("BEST") : "BEST" 를 받겠다. while (*s) { → B, E, S, T 가 끝날때까지 반복한다. n = malloc(sizeof(struct node)); malloc : 컴퓨터 메모리라는 빈 땅에 내가 쓸 공간을 줘 sizeof(struct node) : struct node 의 크기(sizeof)만큼 n = : 새로 지어진 주소를 포인터(리모컨) n에 저장  n->c = *s++; n : 리모컨 -> : 리모컨이 가리키는 집 안으로 들어가라 c : 집 안에 있는 방이름 → n->c 는 방금 만든 노드(n)의 c 라는 칸을 가리킨다. (가리키고 있을 뿐) *s : 현재 s값이 가리키는 값, "B"를 가져옴 s++ : "B"를 줬으니 이제 다음 글자인 "E"를 가리키도록 보따리 위치를 한 칸 옆으로 옮긴다. → *s++ : s에 들어있는 값(BEST)에서 글자 하나를 꺼내서 다음 글자로 손가락을 옮겨라 n->p = h; n->p : n 이 가리키는 노드의 p칸을 열어라 = : 오른쪽에 있는 값을 왼쪽에 복사해서 넣어라 h : 지금 h가 기억하고 있는 주소 'struct node* h = NULL;' 했기 때문에 NULL 이 들어간다.  h = n; → h 의 값에 n 의 값을 넣어라. (h가 이제부터 n이 가리키는 곳을 가리켜라) → n 은 현재 1회전한 'B, NULL' 의 주소이다.  → 이를 반복한다. 반복하게 되면,  } return h; → 반복해서 얻은 h의 값을 리턴해라. 가장 마지막에 얻은 T의 주소값이 리턴됨 int main() { struct node* n = func("BEST"); → 위의 'struct node* func(char* s)'를 호출한다. → func라는 곳에 가서 "BEST"를 주고 결과를 받아온다. while (n) { → 위('return h')에서 얻은 T의 주소값이 n으로 리턴된다. → T의 주소값이 NULL을 만날때까지 반복된다. putchar(n->c); putchar : 출력해라 → T 주소에 있는 c의 값을 출력해라 = T struct node* t = n; struct node* t : t (Temporary)는 임시값을 뜻함. → T의 값을 임시로 저장해둬라. n = n->p; → n의 p 값을 n에 넣어라 free(t); free : 삭제해라 → t의 값을 삭제해라 즉, T가 출력되고, 리모컨은 S로 이동. 이때 T의 노드는 삭제된다. 다음 S 출력, 리모컨은 E로 이동, S 노드 삭제 다음 E 출력, 리모컨은 B로 이동, E 노드 삭제 다음 B 출력, 리코먼은 NULL로 이동, B노드 삭제 n 이 NULL 이므로 반복문 종료 즉, TSEB 출력 |
19. 다음은 TCP통신 과정에서 발생할 수 있는 보안 취약점에 대한 설명이다. 이를 이용한 공격 기법으로 옳은 것은?
- TCP는 연결을 수립하기 위해 클라이언트가 서버에 SYN패킷을 보내고 서버는 SYN-ACK 패킷으로 응답한 후클라이언트가 다시 ACK 패킷을 보내는 3-way-handshake과정을 거친다.
- 이때 공격자는 클라이언트 역할로 수많은 SYN패킷을 서버에 전송한 뒤 마지막 ACK를 고의로 보내지 않아 서버가 연결 대기 상태를 계속 유지하게 만든다.
- 이로 인해 서버의 연결 대기 큐가 가득 차면서 정상적인 접속 요청을 처리하지 못하게 되어 서비스 거부 상태가 발생한다.
| 답: SYN Flooding 1. DoS (서비스 거부 공격) 계열 : 시스템의 자원을 고갈시켜 정상적인 서비스를 방해하는 공격입니다. Smurf (스머프) - IP 위조(Spoofing)와 ICMP Echo 패킷을 이용합니다. - 공격자가 다이렉트 브로드캐스트를 통해 수많은 컴퓨터에 패킷을 보내면, 응답 패킷이 모두 희생자(Victim)에게 집중되게 만듭니다. Ping of Death - 허용 범위를 넘어서는 거대한 크기의 Ping 패킷을 전송합니다. - 패킷이 네트워크를 통과하기 위해 여러 파편(Fragment)으로 나뉘고, 수신 측에서 이를 재조합하는 과정에서 부하가 발생하여 시스템이 다운됩니다. Land Attack - 패킷을 보낼 때 출발지(Source) IP와 목적지(Destination) IP를 희생자의 IP로 동일하게 설정하여 전송합니다. - 희생자는 자신에게 온 패킷을 다시 자신에게 응답하게 되어 무한 루프에 빠집니다. Teardrop - IP 패킷의 재조합 과정에서 사용하는 오프셋(Offset) 값을 조작합니다. - 조각난 패킷들이 서로 중첩되거나 빈 공간이 생기게 하여 수신 측 시스템을 오류로 마비시킵니다. 2. 세션 및 스니핑 관련 공격 : 데이터를 훔쳐보거나 연결 권한을 가로채는 공격입니다. Session Hijacking (세션 하이재킹) - 클라이언트와 서버가 통신 중일 때, TCP Sequence Number를 조작하여 인증된 세션을 중간에서 가로채는 공격입니다. - "세션 가로채기"라고도 합니다. Sniffing (스니핑) - 네트워크상에서 흘러 다니는 패킷을 몰래 엿보는 공격입니다. - 수동적인 공격에 해당하며, 네트워크 카드를 'Promiscuous Mode(무차별 모드)'로 설정하여 작동합니다. ARP Spoofing - 로컬 네트워크(LAN)에서 ARP 메시지를 조작하여, 공격자의 MAC 주소를 게이트웨이나 타겟의 주소인 것처럼 속입니다. - 이를 통해 중간에서 패킷을 가로챌 수 있습니다. 3. 애플리케이션 및 코드 취약점 공격 : 소프트웨어 설계상의 허점을 파고드는 공격입니다. SQL Injection - 웹 사이트의 입력창에 악의적인 SQL 구문을 삽입하여 데이터베이스(DB)를 조작하거나 비정상적인 로그인을 시도하는 공격입니다. XSS (Cross-Site Scripting) - 검증되지 않은 외부 입력을 웹 페이지에 포함시켜 사용자의 브라우저에서 악성 스크립트가 실행되게 하는 공격입니다. (사용자의 쿠키 탈취 등에 사용) Buffer Overflow - 메모리의 정해진 크기(버퍼)보다 더 큰 데이터를 입력하여 인접한 메모리 영역을 덮어쓰고, 복귀 주소(Return Address)를 조작해 공격자의 코드를 실행시키는 기법입니다. |
20. 다음 테이블에서 πTTL(employee)에 대한 연산 결과 값을 작성하시오.

| 답: 1. TTL 2. 부장 3. 대리 4. 과장 5. 차장 πTTL(employee) π : project 연산을 의미하며, 특정 속성(TTL)만 출력해라. TTL : 특정 속성 |
'자격증 요약 > 정보처리기사' 카테고리의 다른 글
| [24년 3회] 정보처리기사 실기 문제 풀이 (0) | 2026.02.24 |
|---|---|
| [25년 1회] 정보처리기사 실기 문제 풀이 (0) | 2026.02.24 |
| [25년 3회] 정보처리기사 실기 문제 풀이 (0) | 2026.02.23 |
| [정보처리기사] UML 다이어그램 정리 (0) | 2026.02.05 |
| [23년 1회 4과목] 정보처리기사 필기 문제 풀이 (0) | 2026.01.30 |