
1. 다음은 UML ( ) 다이어그램이다. 아래 내용을 보고 다이어그램의 관계를 확인하여 명칭을 작성하시오.
- ( )다이어그램이란 시스템을 폴더 모양의( )단위로 구분하여 구성 요소 간의 관계를 표현하는UML구조 다이어그램이다.
- 하나의 ( )안에는 여러 클래스나 하위( )가 포함될 수 있으며, ( )간에는«import», «access», «merge»등의 관계를 통해 의존성(Dependency)을 표현한다.
- 이 다이어그램은 코드의 실제 구조(폴더 구조)와 비슷하게 표현되기 때문에 소프트웨어의 모듈화,재사용성,의존 관계를 시각적으로 설계할 때 자주 사용된다.
| 답: 패키지 (Package) 폴더 모양  «import»: 타 패키지의 요소를 자신의 패키지 안으로 가져오는 것 (네임스페이스 생략 가능). «access»: 타 패키지의 요소를 참조만 하는 것 (사용 시 원래 패키지 이름을 명시해야 함). |
2. 다음은 소프트웨어 테스트 기법 중 하나에 대한 설명이다.
- 소프트웨어 테스트의 구조 기반(화이트박스)기법 중 하나로, 결정 포인트(Decision Point)내에 존재하는 모든 개별 조건식(Atomic Condition)을 대상으로 하는 커버리지 기준이 있다.
- 하나의 결정문(예: if (A && B)또는if (X > 10 || Y == 0))안에는 여러 개의 조건식이 포함될 수 있는데이 커버리지는 각각의 조건식이True와False두 가지 경우를 모두 한 번 이상 만족하도록 테스트 케이스를 설계해야 한다.
- 즉,모든 개별 조건이 두 방향의 결과를 거쳐야“커버되었다”고 판단하지만 그렇다고 해서 전체 결정식(Decision Expression)의 결과(True/False)가 모두 수행된다고 보장하지는 않는다.
[보기] ㄱ.경로(Path) ㄴ.결정(Decision) ㄷ.조건/결정(Condition/Decision) ㄹ.변경 조건/결정(Modified Condition/Decision, MC/DC) ㅁ.다중 조건(Multiple Condition) ㅂ.문장(Statement) ㅅ.분기(Branch) ㅇ.조건(Condition) ㅈ.루프(Loop)
| 답: ㅇ.조건 화이트박스 테스트의 검증 기준 문장 (Statement) 검증 기준 - 소스 코드의 모든 구문이 한 번 이상 수행되도록 테스트 케이스 설꼐 분기 (Branch) 검증 기준(결정 (Decision) 검증 기준) - 소스 코드의 모든 조건문에 대해 조건이 True인 경우와 False인 경우가 한 번 이상 수행되도록 테스트 케이스 설계 조건 (Condition) 검증 기준 - 소스 코드의 조건문에 포함된 개별 조건식의 결과가 True인 경우와 False인 경우가 한 번 이상 수행되도록 테스트 케이스 설계 분기/조건 (Branch/Condition) 기준 - 분기 검증 기준과 조건 검증 기준을 모두 만족하는 설계로, 조건문이 True인 경우와 False인 경우에 따라 조건 검증 기준의 입력 데이터를 구분하는 테스트 케이스 설계 |
3.다음은 유닉스(Unix)또는 리눅스(Linux)환경에서 자주 사용하는 기본 명령어에 대한 설명이다. 각 설명에 맞는 명령어를 보기에서 골라 연결하시오.
1. 현재 작업 중인 디렉터리의 경로를 출력
2. 디렉터리의 내용(파일 및 하위 디렉터리)을 목록으로 표
3. 다른 디렉터리로 이동
4. 파일을 복사
[보기] ls, cd, cp, pwd
| 답: 1. pwd 2. ls 3. cd 4. cp UNIX / LUNUS 기본 명령어 cat : 파일 내용 출력 ls : 디렉터리의 내용을 목록으로 표시 cp : 파일 복사 rm : 파일 삭제 find : 파일 검색 chdir(cd) : 다른 디렉터리 이동 pwd : 현재 작업 중인 디렉터리의 경로를 출력 chmod: 파일 권한(permission) 변경 chown : 파일 소유자 변경 umask : 기본 권한 마스크 fork : 프로세스 복제, 자식 프로세스 생성 exec : 현재 프로세스를 새 프로그램으로 대체 wait : 자식 프로세스 종료 대기 fsck : 파일 시스템 검사 및 복구 mount : 파일 시스템 연결 umount : 파일 시스템 해제 uname : 시스템 정보 출력 |
4. 다음은 오류검출 방식을 설명하는 내용이다.설명의 빈칸(①)~(⑤)에 들어갈 알맞은 용어를<보기>에서 고르시오.
- ( ① ) 코드는 오류 검출과 수정이 모두 가능한 방식이다.
- 재전송 없이 수신 측에서 자체 수정하는 방식을 ( ② ) 방식이라 한다.
- 오류 발생 시 재전송을 요구하는 방식은 ( ③ )이라 한다.
- 데이터 블록 끝에 1비트 검사 비트를 추가하는 방식은 ( ④ ) 검사이다.
- 특정 다항식을 사용하여 오류를 검출하는 방식은 ( ⑤ ) 검사이다.
[보기] CRC, FEC, BEC, NAK, Parity, MD5, BCD, Hamming
| 답: ① Hamming ② FEC ③ BEC ④ Parity ⑤ CRC '해밍 코드(Hamming)'는 검출과 수정이 둘 다 된다 '다항식' = 무조건 CRC '재전송 없이 스스로 수정' = FEC '재전송 요청' = BEC '데이터 블록 끝에 1비트 검사 비트를 추가' = Parity |
5. 다음은 C코드에 대한 문제이다. 아래 코드를 확인하여 알맞는 출력값을 작성하시오.
#include <stdio.h>
struct Test { int i; const char *g; };
int main() {
struct Test test[] = {{1, "AB"}, {2, "DC"}, {3, "EB"}};
struct Test *p = &test[1];
printf("%s", p->g + (p->i - 1));
return 0;
}| 답: C #include <stdio.h> struct Test { int i; const char *g; }; → 구조체의 모양 정의  int main() { struct Test test[] = {{1, "AB"}, {2, "DC"}, {3, "EB"}}; → test[ ] 라는 이름의 구조체 배열이 생성  struct Test *p = &test[1]; → 포인터 p는 test 배열의 '두 번째 요소(test[1])'를 가리킵니다. → 현재 p가 가리키는 값 : 노란색 셀  printf("%s", p->g + (p->i - 1)); → p->g : 주소p가 가리키는 곳의 g값을 나타내라. → 현재 p가 가리키는 g 값은 DC  → (p->i - 1) : 주소 p가 가리키는 i값에서 -1 을 해라 → 현재 p의 값은 2. 그러므로 위의 수식을 진행하면 1이 된다.  : 문자열 DC에서 주소값에 1을 더하면, 첫 번째 글자인 'D'를 건너뛰고 두 번째 글자인 'C'가 시작되는 지점을 가리킨다. 그러므로 답은 C |
6. 다음은 C코드에 대한 문제이다. 아래 코드를 확인하여 알맞는 출력값을 작성하시오.
#include <stdio.h>
int main(void) {
int a = 0;
char str[] = "REPUBLICOFKOREA";
while(str[a] != '\0') ++a;
putchar(str[a-2]);
return 0;
}| 답: E int main(void) { int a = 0; char str[] = "REPUBLICOFKOREA"; → str[ ] 메모리에 문자열을 저장 (이 때, 문자열 끝에 \0 (NULL)도 저장된다.  while(str[a] != '\0') ++a; → str[a] != '\0' : 변수 a는 \0(NULL)이 아닐 때까지 → ++a : a값을 1씩 증가한다. → 즉, a = 15 가 된다. putchar(str[a-2]); → a가 15이므로, 인덱스 13의 문자를 출력하라는 뜻 → 즉, putchar(str[15-2]) = putchar(str[13]) = E ※ putchar(): 문자 하나만 출력합니다. ※ printf("%s", ...): 주소부터 문자열 전체를 출력합니다. ※ printf("%c", ...): 문자 하나를 출력합니다. 그러므로 답은 E |
7. 다음은 C코드에 대한 문제이다. 아래 코드를 확인하여 알맞는 출력값을 작성하시오.
#include <stdio.h>
struct Node {
struct Node* next;
unsigned int x;
};
int main() {
struct Node t1 = {0, 5u};
struct Node t2 = {0, 7u};
struct Node t3 = {0, 11u};
t3.next = &t2;
t2.next = &t1;
struct Node* curr = &t3;
int sum = 0;
while (curr) {
sum = sum * 3 + curr->x;
curr = curr->next;
}
sum = (sum ^ 42u) + 100u;
printf("%u\n", sum);
}| 답: 187 #include <stdio.h> struct Node { struct Node* next; unsigned int x; → Node의 구조  int main() { struct Node t1 = {0, 5u}; struct Node t2 = {0, 7u}; struct Node t3 = {0, 11u}; → 구조체 정의와 데이터 초기화 ※ 숫자 뒤에 붙는 'u'는 이 상수가 'unsigned int 타입'임을 명시하는 접미사. (의미없음)  t3.next = &t2; → t3.next 가 t2 를 가리킴 t2.next = &t1; → t2.next 가 t1 을 가리킴 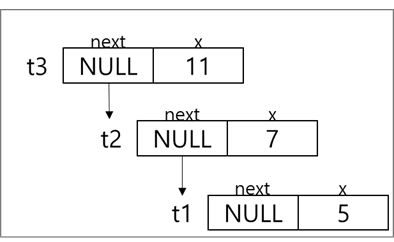 struct Node* curr = &t3; → struct Node 에 포인터 변수(*) curr 을 만들고, 거기에 t3 노드의 주소값을 넣어라  int sum = 0; → 정수형 변수 sum을 만들고 0으로 초기화해라 while (curr) { sum = sum * 3 + curr->x; curr = curr->next; → while (curr) : curr 의 반복문 수행 (첫 번째 반복. t3) sum = sum * 3 + curr->x; → 0 * 3 + 11 = 11 curr = curr->next; → curr을 다음 next 로 보내라. 앞서 t3.next 는 t2로 연결했다. (두 번째 반복. t2) sum = sum * 3 + curr->x; → 11 * 3 + 7 = 40 curr = curr->next; → curr을 다음 next 로 보내라. 앞서 t2.next 는 t1로 연결했다. (세 번째 반복. t1) sum = sum * 3 + curr->x; → 40 * 3 + 5 = 125 curr = curr->next; → curr을 다음 next 로 보내라. 앞서 t1.next 는 NULL 이다. → NULL을 만났으니 더 갈 곳이 없다. 반복문 종료 → sum 의 최종 값은 125 sum = (sum ^ 42u) + 100u; sum ^ 42u → 125 ^ 42  ※ ^ (xor) : 비교해서 다르면 1로 반환, 같으면 0으로 반환 sum = (sum ^ 42u) + 100u; → 87 + 100 = 187 printf("%u\n", sum); → 187 값을 반환한다. |
8. 아래 코드는 Machine 이라는 인터페이스를 정의하고 WashingMachine 클래스에서 해당 인터페이스를 사용하고자 한다. 빈칸에 들어갈 올바른 키워드를 작성하시오.
interface Machine {
void run();
}
class WashingMachine (____빈칸____) Machine {
private String name;
public WashingMachine() {
this.name = "LGWasher";
}
public void run() {
System.out.println("Washing machine running");
}
}
public class Main {
public static void main(String[] args) {
WashingMachine wm = new WashingMachine();
wm.run();
}
}| 답: implements '부모 클래스를 상속받는다'는 맥락이면 extends '인터페이스를 구현한다'는 맥락이면 implements |
9. 다음은 파이썬에 대한 문제이다. 아래 코드를 확인하여 출력값에 알맞는 값을 작성하시오.
data = [[3,5,2,4,1], [4,5,1], [4,4,1,5,4], [4,5]]
result = {}
for index, lis in enumerate(data):
result[index] = (sum(lis), len(lis))
print(result){0: (①,②), 1: (③,④), 2: (⑤,⑥), 3: (⑦,⑧)}
| 답: ① = 15 ② = 5 ③ = 10 ④ = 3 ⑤ = 18 ⑥ = 5 ⑦ = 9 ⑧ = 2 data = [[3,5,2,4,1], [4,5,1], [4,4,1,5,4], [4,5]] → 2차원 리스트 형태 ' [ ' 으로 알 수 있다.  ※data[0] = [3,5,2,4,1] : (전체 리스트에서 0번 행 전체를 가져와라) ※data[0][0] = 3 : (0번행 안 에서 다시 0번 열의 값을 가져와라) result = {} → result는 딕셔너리로 정의한다. → '{}' (딕셔너리) 키(key)와 값(value)을 한 쌍으로 묶어서 저장하는 상자 for index, lis in enumerate(data): → index 에 숫자 0,1,2,3이 차례대로 들어간다. (인덱스 '번호' 그 자체가 들어감) → lis에 daa 안의 각 서브 리스트들이 차례대로 들어간다. (data[0]인 [3,5,2,4,1] → 쉽게 생각하면, 그냥 위에 정의한 2차원 리스트를 꺼낼 수 있게 됐다. 로 이해 ※ enumerate 인덱스(번호)와 값을 동시에 꺼내주는 함수 result[index] = (sum(lis), len(lis)) ※ result[index] : 저장할 위치(이름표) ※ (sum(lis), len(lis)) : 저장할 내용물(계산 결과) ※ = : 오른쪽의 결과를 왼쪽에 대입 sum(lis) : 합계 구하기 → 현재 반복문에서 꺼내온 리스트(lis) 안에 있는 모든 숫자를 더함 → 예. lis 가 [3,5,2,4,1] 이라면 3+5+2+4+1 = 15 라는 숫자를 만듦 len(lis) : 개수 구하기 → 리스트(lis) 안에 데이터 몇 개 들어있는지 셈 → 예. lis 가 [3,5,2,4,1] 이라면 숫자가 5개 있으므로 결과는 5 가 됨 (sum(lis), len(lis) : 튜플로 묶기 → sum(lis)의 결과값과 len(lis)의 결과값을 소괄호로 묶어 하나의 세트로 만듦 → 예. (15, 5) 라는 데이터 덩어리가 됨 result[index] = (sum(lis), len(lis)) → (sum(lis), len(lis) 의 값을 result[index] 에 저장 → 예. result[0] = (15, 5) 가 됨 for index, lis in enumerate(data): result[index] = (sum(lis), len(lis)) 반복시행  print(result) → {0: (15,5), 1: (10,3), 2: (18,5), 3: (9,2)} |
10. 다음은 테이블에서 조건값을 실행한 화면이다. 이에 대한 알맞는 결과값을 작성하시오.

| 답: 4 SELECT COUNT(*) CNT → 아래의 조건에 일치하는 행의 개수를 세어서 CNT라는 이름으로 출력 ※행의 개수 = COUNT(*) FROM T1 A CROSS JOIN T2 B ※ CROSS JOIN : 모든 가능한 조합을 만드는 조인 ※ T1 A : T1 테이블을 A라고 표현하겠다. → T1의 행의 수 : 3개 → T2의 행의 수 : 2개 → 즉, 총 6개(2x3)의 데이터 쌍이 만들어짐  WHERE A.NAME LIKE B.RULE → 조건. A 테이블의 NAME 과 B 테이블의 RULE 가 일치(LIKE) 하는 것  즉, 4개가 일치한다. ※ LIKE 연산자의 특수 문자 s%: 's'로 시작하는 모든 것 (예: smith, scott, sun) %s: 's'로 끝나는 모든 것 (예: bus, lens) %s%: 's'가 어디든 포함된 것 (예: asset, bus, smith) s_: 's'로 시작하는 딱 2글자 (예: so, si) ※JOIN의 종류 INNER JOIN : 조건에 맞는 교집합만 추출 LEFT OUTER JOIN: 왼쪽 테이블 전체 + 오른쪽 일치 항목 CROSS JOIN : 모든 경우의 수 (카테시안 곱) |
11. 다음 설명에 해당하는 인증 기술을 쓰시오.
- 한 번 사용하면 즉시 폐기되어 재사용이 불가능하다.
- 서버와 토큰(또는 앱)은 시간 동기화나 카운터 기반 방식으로 매번 새로운 값을 생성하고, 내부 검증은 해시 함수를 이용한 방식으로 서버에 평문을 저장하지 않도고 유효성을 확인할 수 있다.
- 이 특성 때문에 은행 인증 등 고보안 영역에서 널리 사용되며 재전송 공격 방지와 사용자 편의성을 동시에 만족한다.
| 답: OTP 인증 관련 기술 OTP - 한 번 사용 후 즉시 폐기되는 일회용 비밀번호를 생성하는 기술 - 시간 동기화(TOTP)나 카운터 기반(HOTP) 방식을 사용하며 재전송 공격(Replay Attack)을 방지함 SSO (Single Sign-On) - 한 번의 로그인으로 여러 서비스를 이용 - 사용자 편의성 극대화 2FA / MFA - 두 가지 이상의 인증 수단을 결합 - ID/PW + OTP 조합이 대표적 Biometrics (생체 인증) - 지문, 홍채, 정맥 등 신체 정보 활용 - 위변조가 어렵고 분실 위험 없음 i-PIN - 주민등록번호 대신 사용하는 개인식별번호 - 웹사이트 주민번호 수집 방지용 OAuth - 제3의 서비스(구글, 카카오 등)에 권한 위임 - '카카오로 로그인하기'의 핵심 기술 SAML (Security Assertion Markup Language) - 주로 기업 환경에서 SSO를 구현하기 위해 사용하는 XML 기반의 표준 데이터 포맷 - OAuth가 '권한'에 집중한다면 SAML은 '인증 정보 전달'에 더 집중 OpenID Connect(OIDC) - OAuth 2.0 기술 위에서 돌아가는 인증 레이어 - OAuth가 권한 열쇠라면, OIDC는 신분증이라고 이해 |
12. 다음은 Java의 상속과 생성자 호출에 관한 코드이다. 밑줄에 알맞은 단어를 작성하시오.
class Rectangle {
int width, height;
Rectangle(int width, int height) {
this.width = width;
this.height = height;
}
}
class Square extends Rectangle {
Square(int a) {
____(a, a);
}
int getSquareArea() {
return width * height;
}
}
public class Main {
public static void main(String[] args) {
Square sq = new Square(10);
System.out.println(sq.getSquareArea());
}
}| 답: super super(): 자식 클래스에서 부모 클래스의 생성자를 호출할 때 사용하는 키워드  |
13. 다음은 인증 및 자원 접근 방식에 대한 설명이다. 알맞은 단어를 작성하시오.
- 사용자가 새로운 사이트에 가입하지 않고 평소에 이용하던 서비스의 계정으로 로그인할 수 있게 해주는 기술이다.
- 사용자의 비밀번호는 절대 전달되지 않으며 사용자가 승인한 범위에 대해서만 접근 권한이 위임된다.
- 이 방식은 직접 인증(Authentication)을 수행하지 않고 '인가(Authorization)' 절차를 통해 접근 권한을 제3자에게 부여한다.
- 인증 완료 후,서비스 제공자는Access Token을 발급하며 애플리케이션은 이 토큰을 이용해API를 호출하여 필요한 정보에 접근한다.
- 대표적인 예는 소셜 로그인이며SSO(Single Sign-On)과 달리동일 시스템 내 인증이 아니라 서로 다른 서비스 간의 권한 위임에 초점이 맞춰져 있다.
| 답: OAuth 인증 관련 기술 OTP - 한 번 사용 후 즉시 폐기되는 일회용 비밀번호를 생성하는 기술 - 시간 동기화(TOTP)나 카운터 기반(HOTP) 방식을 사용하며 재전송 공격(Replay Attack)을 방지함 SSO (Single Sign-On) - 한 번의 로그인으로 여러 서비스를 이용 - 사용자 편의성 극대화 2FA / MFA - 두 가지 이상의 인증 수단을 결합 - ID/PW + OTP 조합이 대표적 Biometrics (생체 인증) - 지문, 홍채, 정맥 등 신체 정보 활용 - 위변조가 어렵고 분실 위험 없음 i-PIN - 주민등록번호 대신 사용하는 개인식별번호 - 웹사이트 주민번호 수집 방지용 OAuth - 제3의 서비스(구글, 카카오 등)에 권한 위임 - '카카오로 로그인하기'의 핵심 기술 SAML (Security Assertion Markup Language) - 주로 기업 환경에서 SSO를 구현하기 위해 사용하는 XML 기반의 표준 데이터 포맷 - OAuth가 '권한'에 집중한다면 SAML은 '인증 정보 전달'에 더 집중 OpenID Connect(OIDC) - OAuth 2.0 기술 위에서 돌아가는 인증 레이어 - OAuth가 권한 열쇠라면, OIDC는 신분증이라고 이해 |
14. 다음 아래의 테이블을 확인하여 R%S의 결과를 테이블 형태로 기재하시오.

답: 디비전(Division) 연산 : S테이블에 있는 걸 다 가진 것을 찾는 것 1) 공통 속성 확인: 두 테이블에서 이름이 같은 열(속성)을 찾습니다. 여기서는 B 열입니다.  2) S 테이블의 값 확인: S 테이블의 B 열에는 '{b1, b3}'이 들어 있습니다.  3) 조건 매칭 (핵심): R 테이블의 A 열 값 중, S 테이블에 있는 b1과 b3을 '모두' 가지고 있는 값을 찾습니다.  a1: R 테이블에서 b1과 연결되어 있고, b3과도 연결되어 있습니다. (S의 모든 조건 충족!) a2: R 테이블에서 b2와만 연결되어 있습니다. b1이나 b3이 없으므로 탈락입니다. 즉, R 테이블에서 S 테이블과 겹치는 열(B)을 제외한 나머지 열(A)만 남게 됩니다. 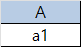 ※ 관계 대수 연산 셀렉션(Selection, σ): 조건에 맞는 '행(Tuple)'을 선택 (가로로 자르기) 프로젝션(Projection, π): 원하는 '열(Attribute)'만 선택 (세로로 자르기) 조인(Join, ⋈): 공통 속성을 중심으로 두 테이블을 합침 카테시안 곱(Cartesian Product, ×): 모든 가능한 조합 생성 |
15. C언어 출력값 (비트 연산) 다음 코드의 출력값을 작성하시오.
#include <stdio.h>
int main() {
int x = 7, y = 4, z;
z = y % 3 < 3 ? 2 : 1;
z = z & z >> 1;
z = x > 5 && z <= 3 ? z * x : z / x;
printf("%d", z);
return 0;
}| 답: 0 int main() { int x = 7, y = 4, z; → 초기값 정의 ※연산 순서 : 왼쪽부터 오른쪽, 연산 우선 법칙에 따라 z = y % 3 < 3 ? 2 : 1; y % 3 : 7 % 3 = 1 (%는 나머지를 구한다.) y % 3 < 3 : 1 < 3 = 참 y % 3 < 3 ? 2 : 1; : z = 2 (조건 ? 참 : 거짓) z = z & z >> 1; z >> 1 : 2 >>1 = 1 → '>>' 시프트 연산자 : 오른쪽으로 1비트 밀어라. 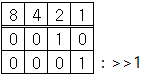 z & z >> 1 : 2 & 1 = 0 → '&' AND 연산자 : 이진수 비교해서 일치하면 1, 불일치면 0  z = x > 5 && z <= 3 ? z * x : z / x; x > 5 : 7 > 5 = 참 && : 둘 다 참이어야 참이 되므로, 다음 연산도 확인한다. (거짓이었다면 다음 연산 확인 안 해도 됨) z <= 3 : 0 <= 3 = 참 z = x > 5 && z <= 3 : 참 && 참 = 참 z * x : 0 * 7 = 0 (참 값이 반환되서 계산된다) printf("%d", z); → 0 값 도출 |
16. 관계형 데이터베이스 개념에 대한 설명이다. 빈칸에 용어를<보기>에서 골라 순서대로 쓰시오
ㄱ. 테이블에서 한 행(Row)을 의미하며,하나의 레코드를 구성하는 요소
ㄴ. 실제 데이터가 저장되어 있는 테이블의 내용 전체를 의미하며,데이터의 상태를 나타낸다.
ㄷ. 테이블에 저장된 행(Row)의 총 개수를 의미한다.
[보기] 스키마(Structure), 속성(Attribute), 튜플(Tuple), 차수(Degree), 인스턴스(Instance), 카디널리티(Cardinality)
| 답: ㄱ.튜플 ㄴ.인스턴스 ㄷ.카디널리티 스키마 (Schema) - 데이터베이스의 구조(Structure)와 제약 조건에 관한 전반적인 명세를 정의한 '틀' - 속성, 개체, 관계 등을 정의. → '구조적 정의', '데이터베이스의 뼈대' 속성 (Attribute) - 데이터베이스를 구성하는 가장 작은 논리적 단위이며, 파일 구조상의 '항목(Field)' 또는 '열(Column)' - 개체의 특성을 기술합니다. 튜플 (Tuple) - 테이블 내의 한 행(Row)을 의미하며, 하나의 레코드(Record)와 같음 - 속성들의 모임으로 구성됩니다. 차수 (Degree) - 하나의 릴레이션(테이블) 안에 있는 속성(열)의 전체 개수 - '세로 줄이 몇 개인가' 카디널리티 (Cardinality) - 하나의 릴레이션(테이블) 안에 있는 튜플(행)의 전체 개수 - '가로 줄이 몇 개인가' 인스턴스 (Instance) - 특정 시점에 데이터베이스에 들어있는 실제 데이터 값들의 집합 - 스키마는 잘 변하지 않지만, 인스턴스는 데이터의 삽입/삭제에 따라 수시로 변함 |
17. 다음은 Java에 대한 코드이다. 알맞는 출력값을 작성하시오.
enum Tri {
A("A"),
B("AB"),
C("ABC");
private String code;
Tri(String code) {
this.code = code;
}
public String code() {
return code;
}
}
public class Main {
public static void main(String[] args) {
Tri t = Tri.values()[Tri.A.name().length()];
System.out.print(t.code());
}
}| 답: AB enum Tri { A("A"), B("AB"), C("ABC"); → Tri는 enum 타입이라는 뜻 (※enum : 열거형) → 각 상수는 문자열을 가진다. 예. B 상수는 "AB"라는 문자열을 가짐 private String code; → 위에서 정의한 상수(A,B,C)가 개인적으로 가질 데이터 공간을 선언 Tri(String code) { this.code = code; → enum의 생성자. 상수가 처음 만들어질 떄 괄호 안에 적어준 값("A","AB","ABC")을 code 란 이름으로 저장  ※enum에는 자동으로 name이란 변수가 만들어진다. (부모 클래스 안에 이미 만들어진 메서드를 가져오는 것) public String code() { return code; → code 에 들어있는 값을 꺼내주는 메서드 → 마지막 print(t.code())에서 t.code()값이 이곳에서 호출되는 것 public class Main { public static void main(String[] args) { Tri t = Tri.values()[Tri.A.name().length()]; Tri.A : 먼저 메모리에 미리 생성되어있는 A라는 열거형 상수 찾아감 (결과값 : Tri.A) Tri.A.name() : 자바의 모든 enum이 기본으로 가지고 있는 메서드로 점프 (결과값 : A) Tri.A.name().length() : 방금 가져온 문자열 "A"의 length() 메서드(문자열 길이 표시)로 이동 (결과값 : 1) Tri.values()[Tri.A.name().length()]; : Tri 클래스가 내부적으로 관리하는 배열로 연결 → Tri.values([1]) : 배열의 인덱스[1]의 값을 호출 = Tri.B (※ Tri.values 는 모든 상수를 모아놓은 목록(배열) : {A, B, C}) System.out.print(t.code()); → t.code() : B에 들어있는 code 는 "AB" 그러므로 AB가 출력됨. |
18. 다음은 정보보안에서 사용하는 접근통제(Access Control)방식에 대한 설명이다. 설명에 해당하는 접근통제 모델을<보기>에서 골라 빈칸에 작성하시오.
( 1 ) 중앙에서 보안 정책을 일괄적으로 설정하며,주체(사용자)가 임의로 수정하거나 변경할 수 없다.주로 군사 기밀,국가 보안과 같은 높은 보안 수준이 요구되는 환경에서 사용된다.보안 등급(Top Secret / Secret / Confidential등)에 따라 접근 여부가 결정된다.
( 2 ) 조직 내에서 부여된 직무나 역할(Role)에 따라 접근 권한을 부여하는 방식이다.개별 사용자에게 직접 권한을 설정하지 않고,역할에 권한을 묶어 부여하기 때문에 관리가 용이하며직무 변경 시 역할만 변경하면 된다.
( 3 ) 자원의 소유자(Owner)가 해당 자원에 대한 접근 권한을 자유롭게 부여하거나 회수할 수 있는 방식이다. 파일이나 폴더의 소유자가 읽기/쓰기/실행 권한을 설정하는 것이 대표적인 예로사용자의 임의 설정이 가능해 보안성이 상대적으로 낮다.
[보기] DAC, MAC, RBAC
| 답: (1) MAC (2) RBAC (3) DAC ① DAC (임의적) - 데이터의 소유자가 권한을 결정한다 - 사용자의 신분에 따라 권한을 부여한다 - 유연성이 높다. ② MAC (강제적) - 시스템(중앙)이 권한을 결정한다 - 보안 등급이나 규칙에 따른다 - 비밀 등급(Label)을 부여한다 ③ RBAC (역할 기반) - 직무나 역할에 따라 부여한다 - 인사 이동이나 변경 시 관리가 쉽다 - 사용자와 권한 사이에 역할이 존재한다  |
19. 다음은테스트케이스의 구성요소에 대한 설명이다. 괄호 ( ) 안에 들어갈 알맞는 보기를 고르시오.

[보기] ㄱ.테스트 조건 ㄴ.테스트 환경 ㄷ.테스트 유형 ㄹ.테스트 데이터 ㅁ.예상 결과 ㅂ.수행 단계 ㅅ.성공/실패 기준
| 답: (왼쪽부터) ㄱ. 테스트 조건 ㄹ. 테스트 데이터 ㅁ. 예상 결과 '화면 상태'가 적혀 있으면? → 조건/환경 '아이디, 비번' 같은 값이 적혀 있으면 → 데이터 '성공, 실패' 같은 결과가 적혀 있으면? → 결과  |
20. 다음은SQL에 관한 문제이다.아래A테이블을 참고하여 쿼리의 결과를 작성하시오.

[SQL]
SELECT count(col2) FROM A WHERE col1 IN (2, 3) OR col2 IN (3, 5)
| 답: 4 SQL의 역순으로 본다. [조건] WHERE col1 IN (2, 3) OR col2 IN (3, 5) col1 IN (2, 3)  col2 IN (3, 5)  col1 IN (2, 3) OR col2 IN (3, 5)  → OR(또는) 이므로 모두 포함된다. [테이블] FROM A [출력] SELECT count(col2) ※ COUNT(*): 조건에 맞는 모든 행의 개수를 셉니다 (NULL 포함). ※ COUNT(컬럼명): 해당 컬럼의 값이 NULL이 아닌 행의 개수만 셉니다.  → NULL이 아닌 값을 세므로, 4개가 나온다. |
'자격증 요약 > 정보처리기사' 카테고리의 다른 글
| [25년 1회] 정보처리기사 실기 문제 풀이 (0) | 2026.02.24 |
|---|---|
| [25년 2회] 정보처리기사 실기 문제 풀이 (0) | 2026.02.24 |
| [정보처리기사] UML 다이어그램 정리 (0) | 2026.02.05 |
| [23년 1회 4과목] 정보처리기사 필기 문제 풀이 (0) | 2026.01.30 |
| [23년 2회 4과목] 정보처리기사 필기 문제 풀이 (0) | 2026.01.30 |